Développeur web orienté données, avec une profonde sensibilité pour la Data et l’ingénierie des systèmes. Actuellement en recherche d'une
alternance en Data Engineering dans le cadre d’un Master.
J'ai acquis des compétences solides en développement web et en gestion de données à travers divers projets personnels et professionnels. Mon objectif est de contribuer à des projets innovants qui allient technologie et données.
Compétences :
💻 HTML
🎨 CSS
⚙️ JavaScript
🐘 PHP
🐍 Python
🗄️ SQL
🌀 Airflow
⚡ Spark
⚛️ React.js
🧱 Symfony
🌐 Django
🐳 Docker
📊 Streamlit
📈 Kibana
📦 Git
Mes projets personnels
Mes projets web intègrent des interfaces responsive, connectées à des bases de données fiables et performantes.
Côté data, ils couvrent l’ensemble de la chaîne de traitement, de l’ETL orchestré avec Airflow et traité avec Spark, jusqu’à la création de dashboards interactifs pour valoriser les données.
L’ensemble des applications est conteneurisé avec Docker pour un déploiement cohérent et reproductible.
Tous les projets sont hébergés sur un serveur OVH avec nom de domaine personnalisé.
L’accès est sécurisé et reflète un environnement de production.
Applications Web :
Garage (Symfony)
Montres (Django)
Pokedex 6G (Django)
Applications Data :
Data Ecommerce (Airflow)
Data Meteo (Airflow)
Data Avis (Airflow)
Data Bank (Airflow, Kibana, Kafka)
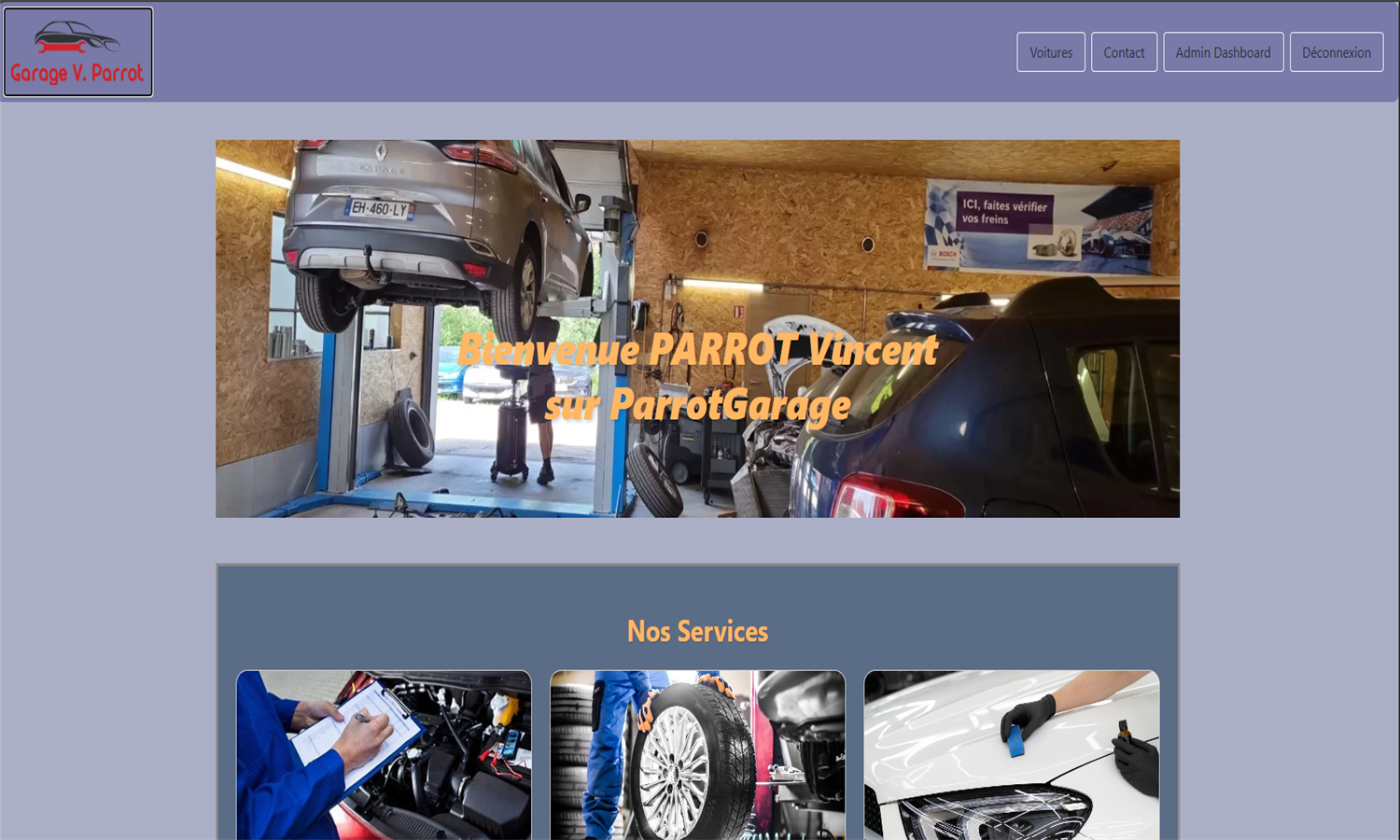
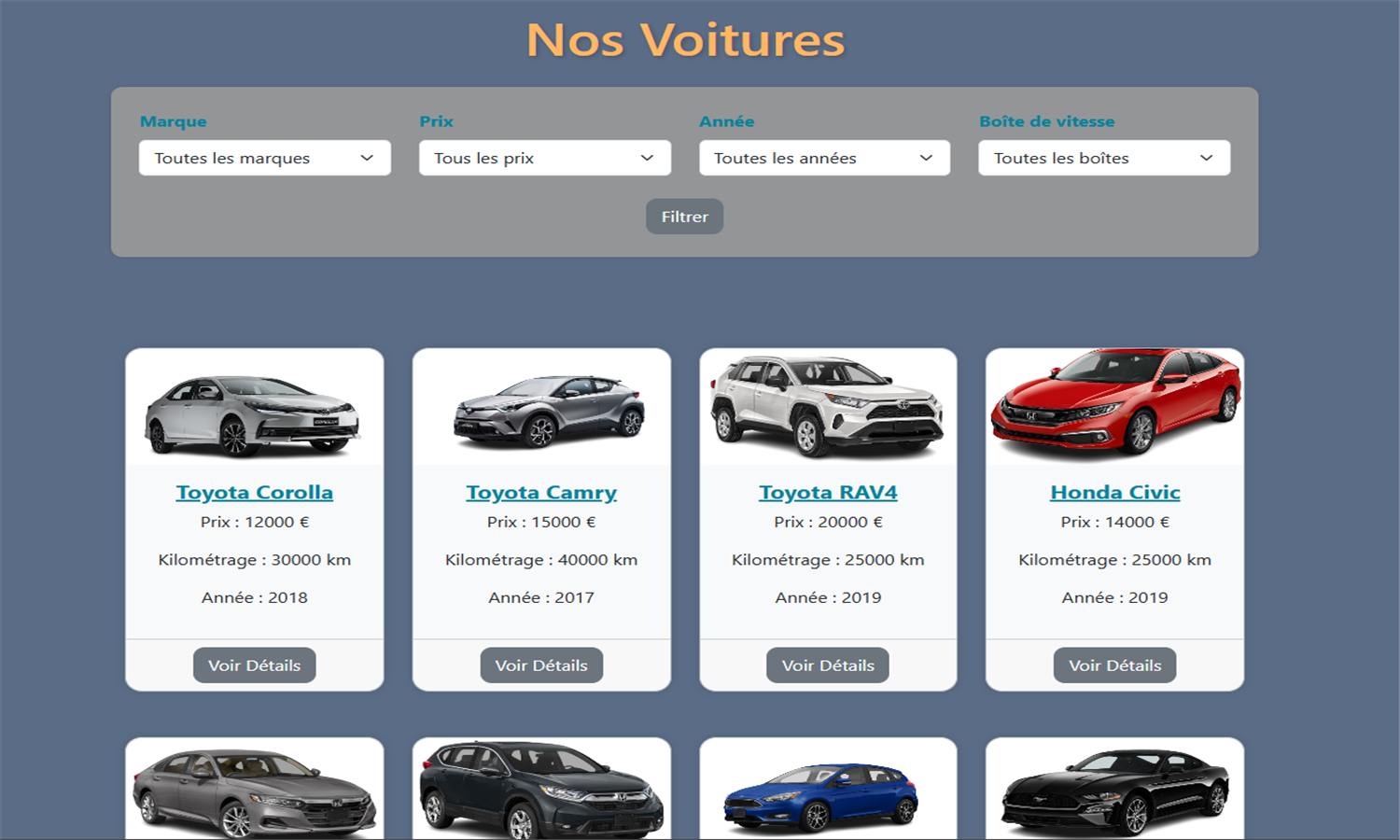
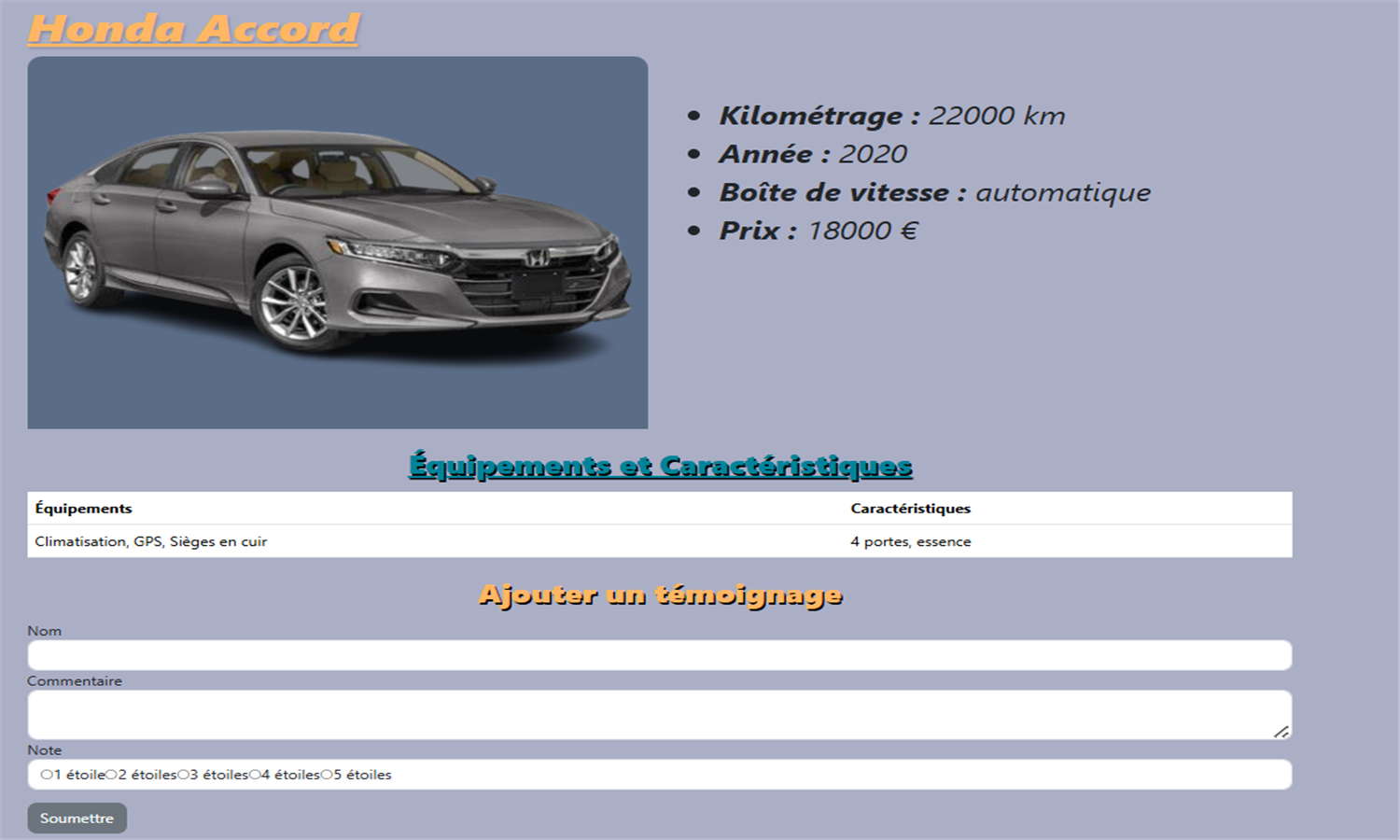
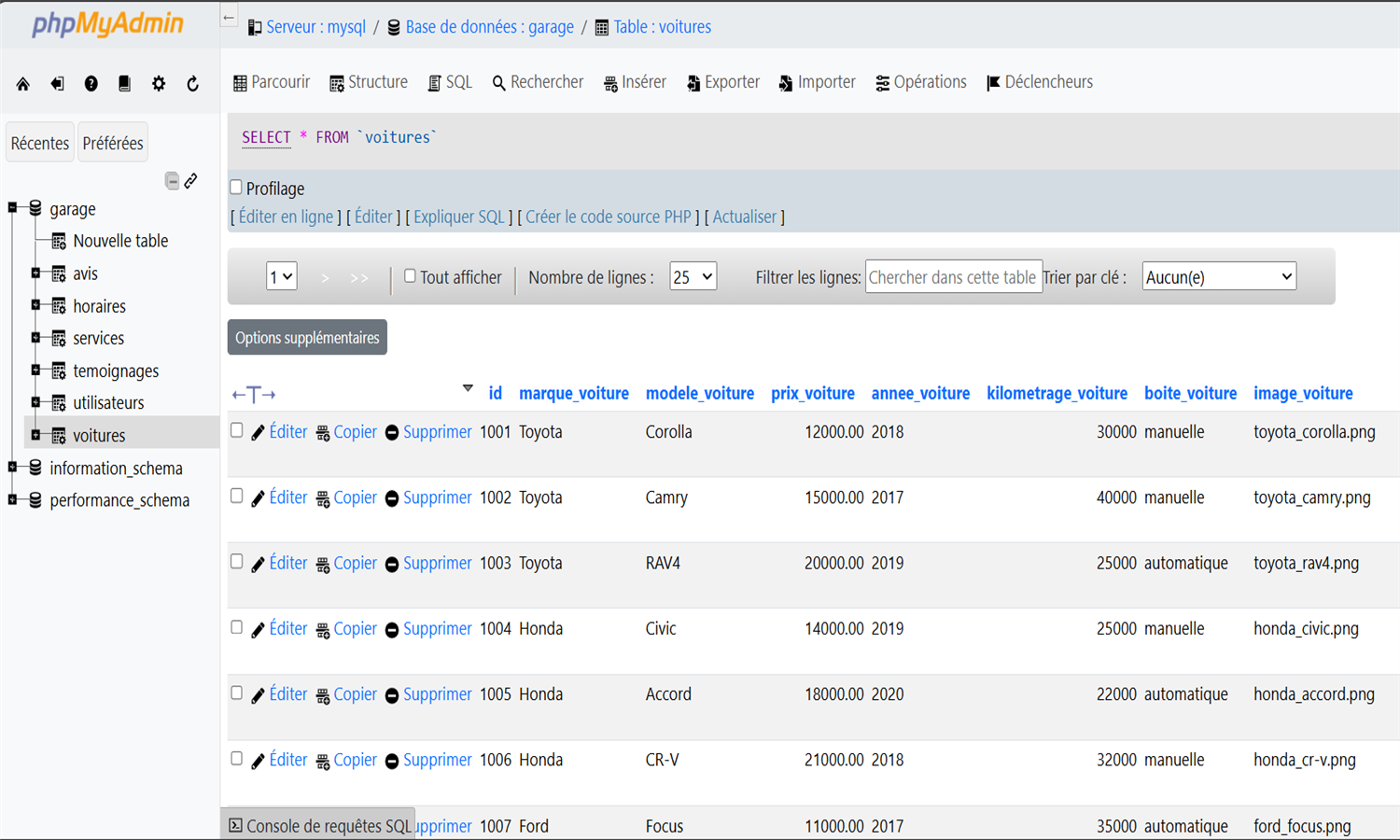
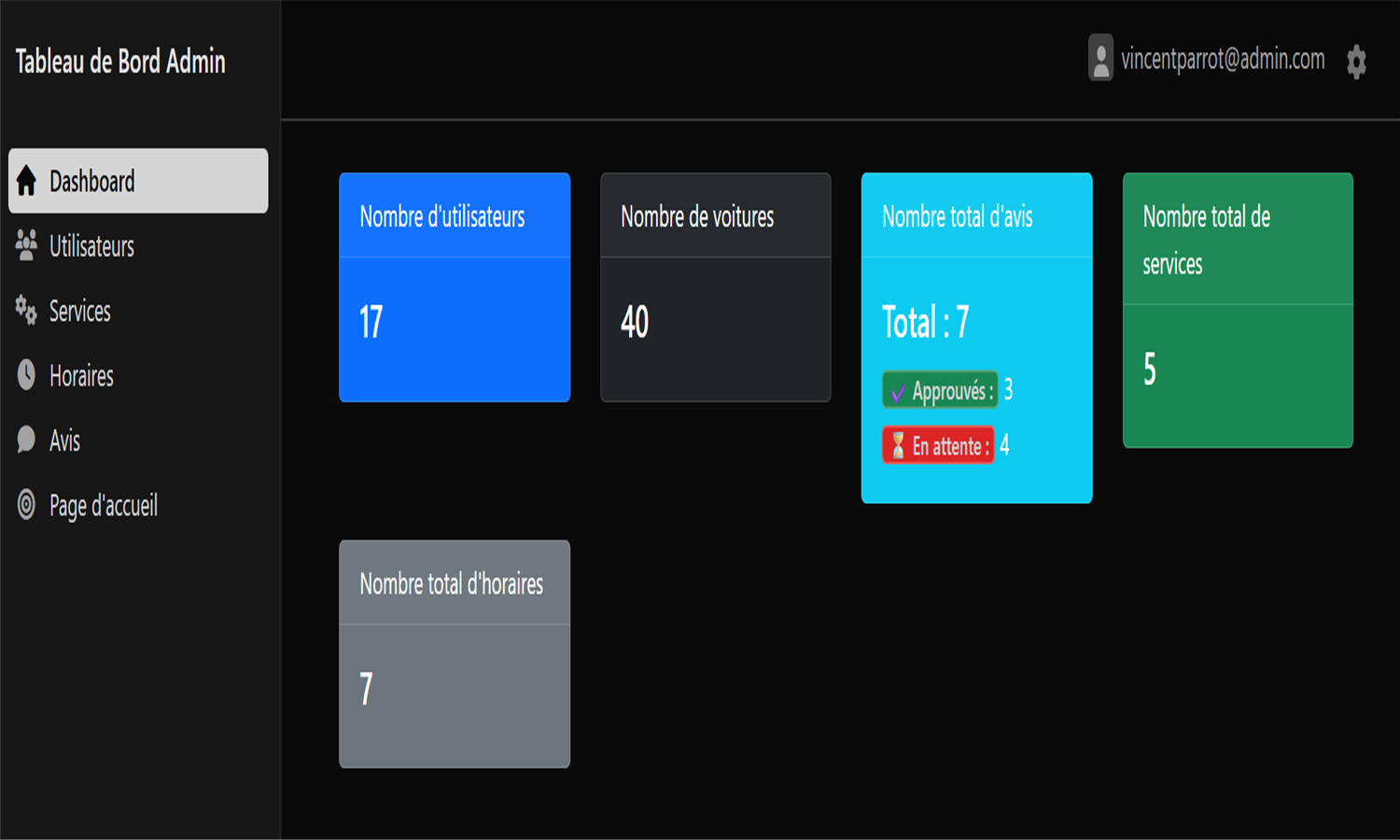
🔧 Garage (Symfony)
Application de gestion de garage automobile avec CRUD complet
Développée avec Symfony 7.1, cette application propose une interface complète pour gérer voitures, utilisateurs, avis, témoignages et services.
Les rôles "Admin" et "Employé" offrent des accès adaptés via des dashboards EasyAdmin.
Les administrateurs disposent d'un contrôle total, tandis que les employés gèrent uniquement leurs entités liées.
L'envoi des messages via le formulaire de contact est assuré par l'API Firebase.
L’architecture suit le modèle MVC avec des entités bien structurées. Seul le rôle visiteur est accordé avec une inscription effectuée sur le site.
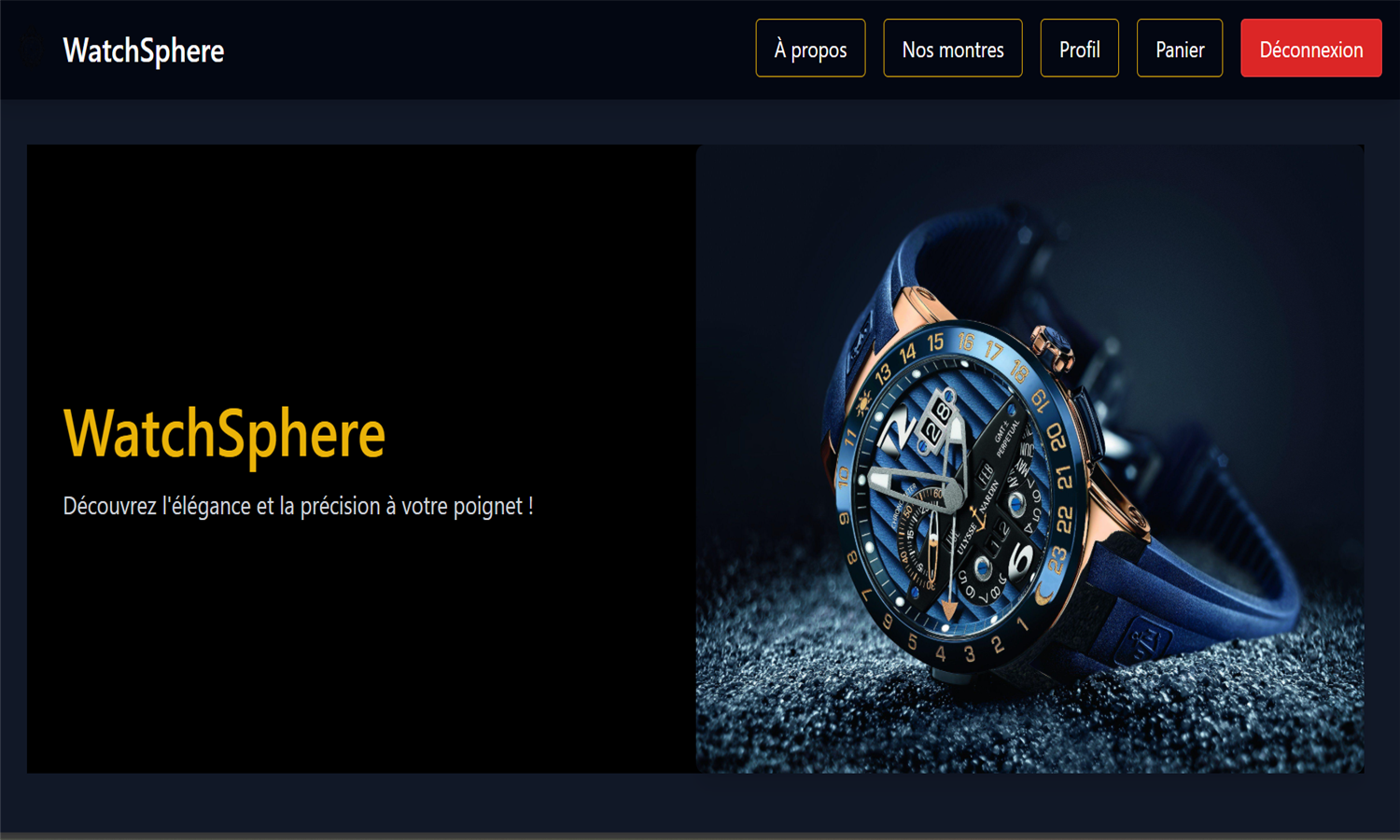
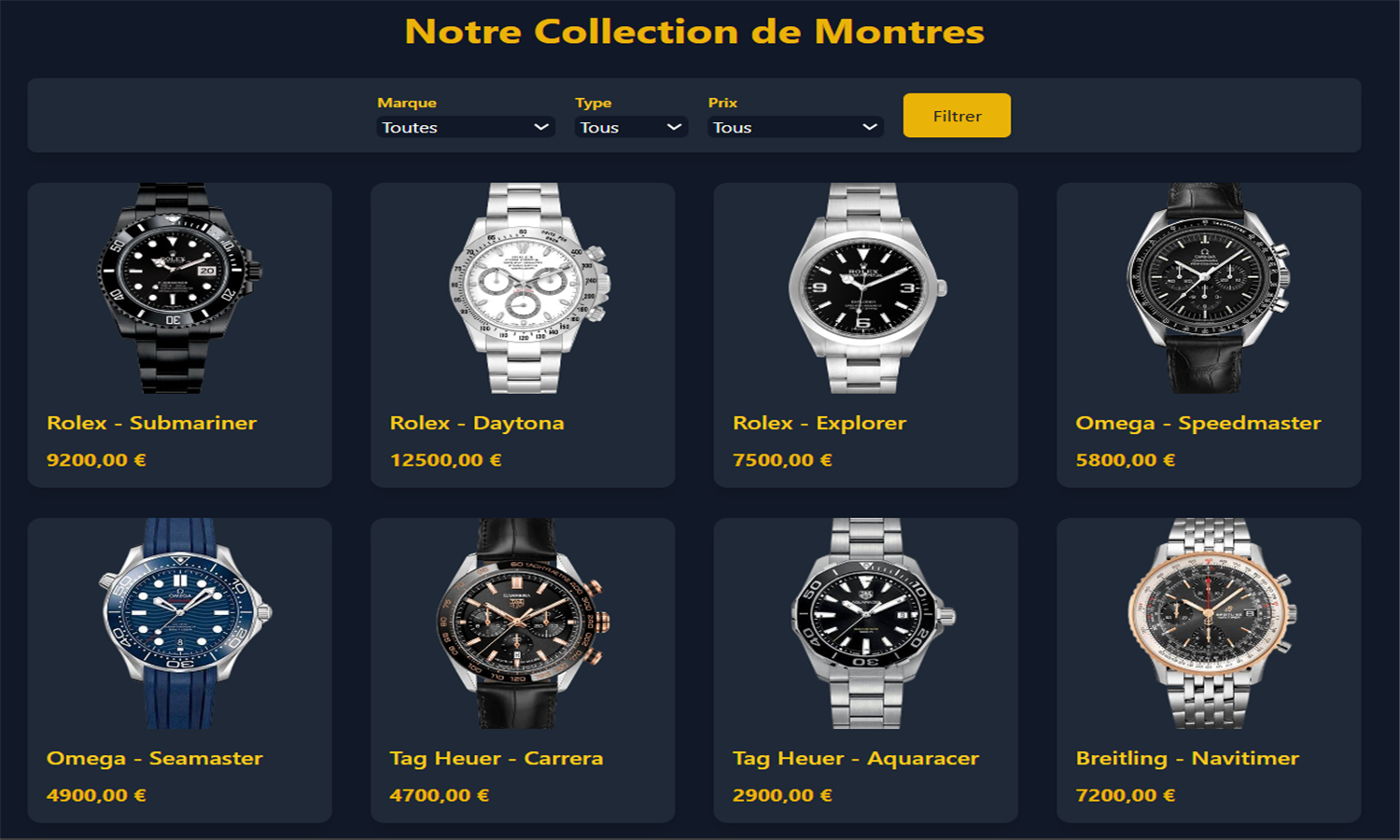
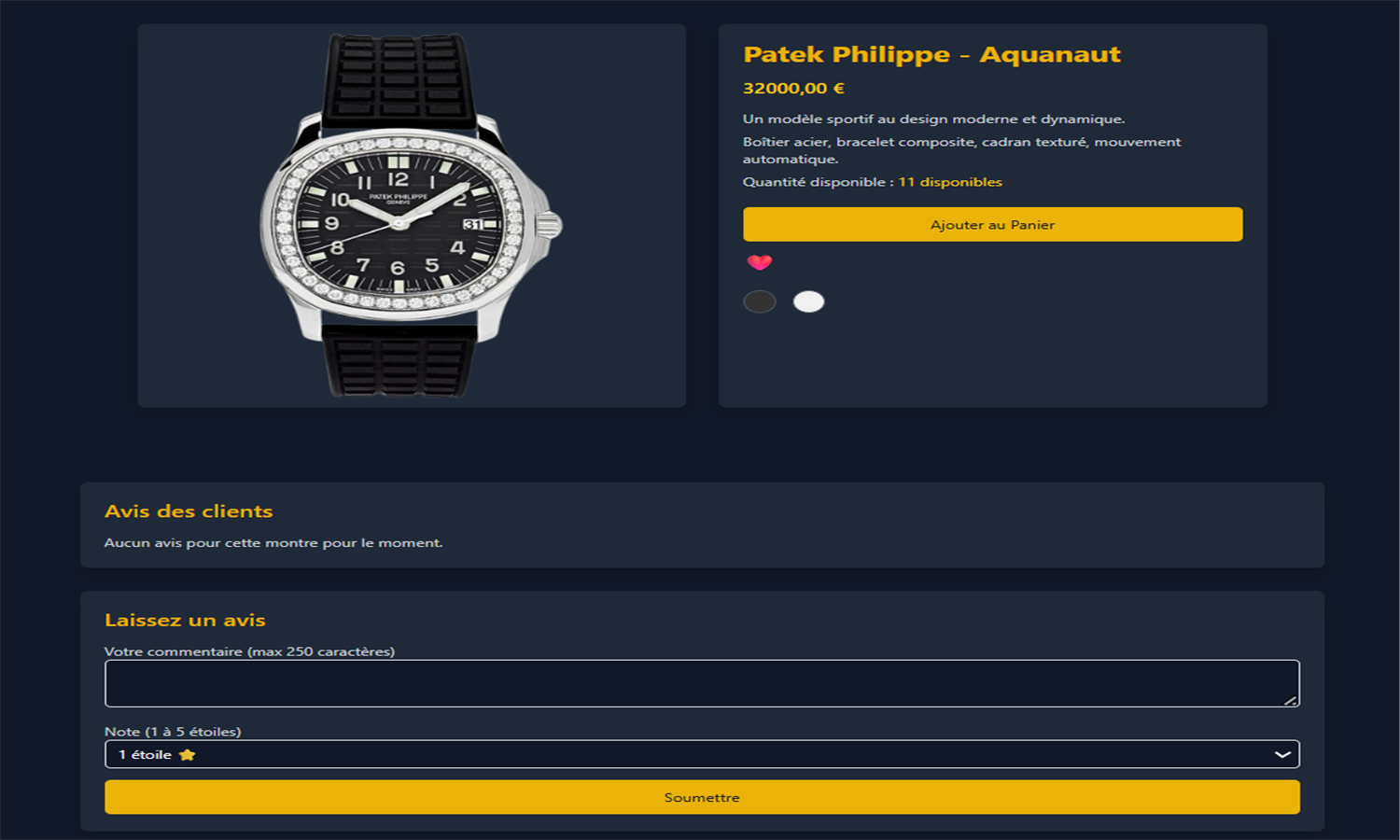
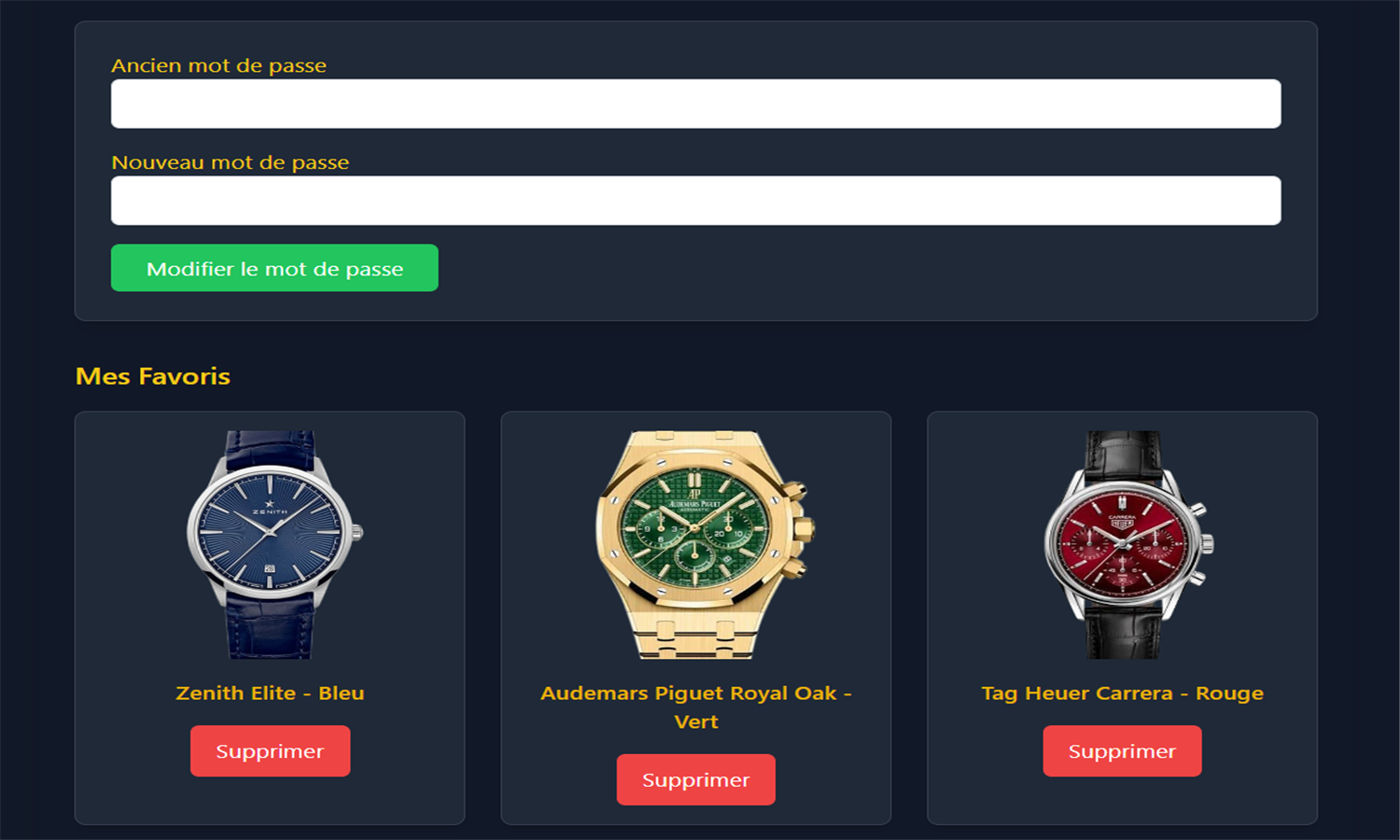
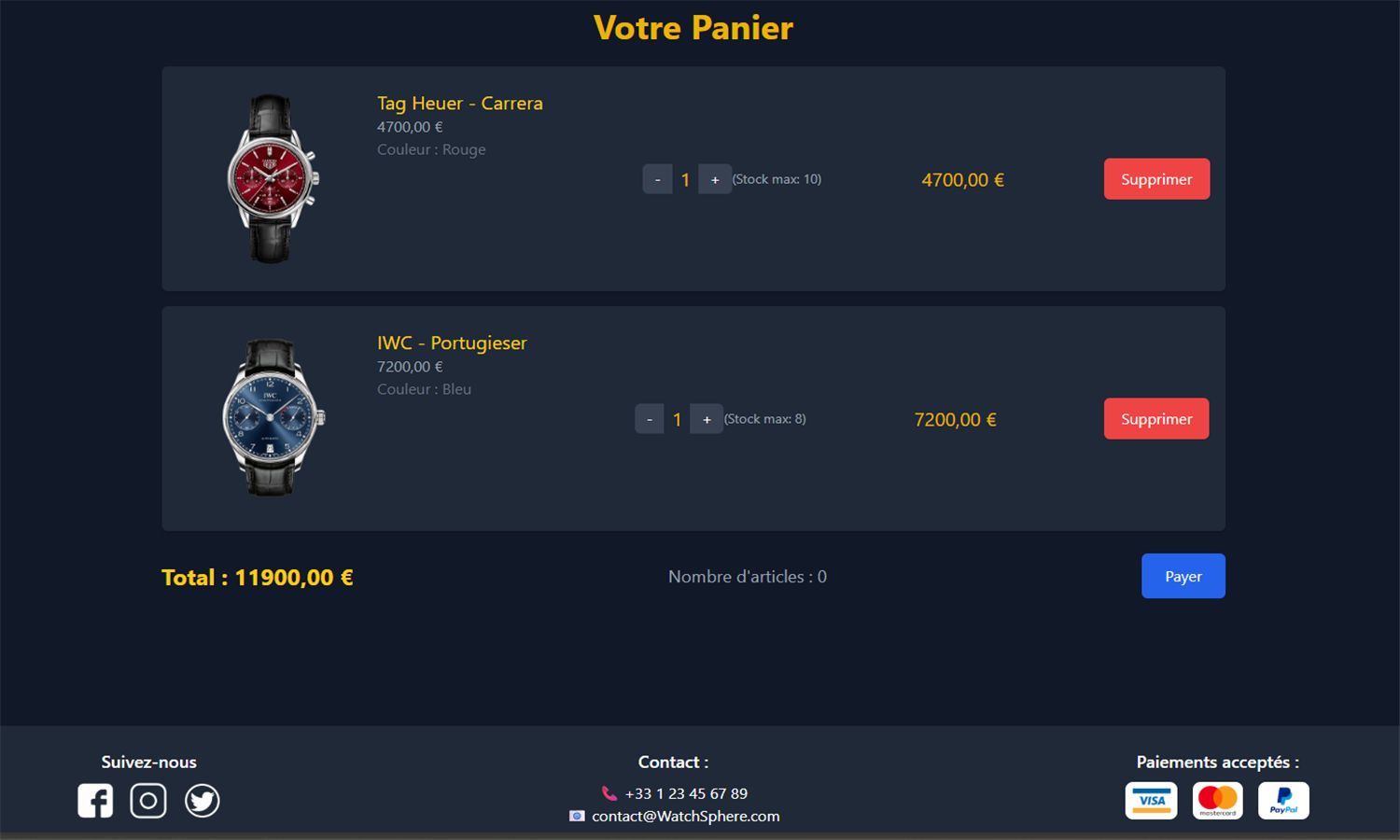
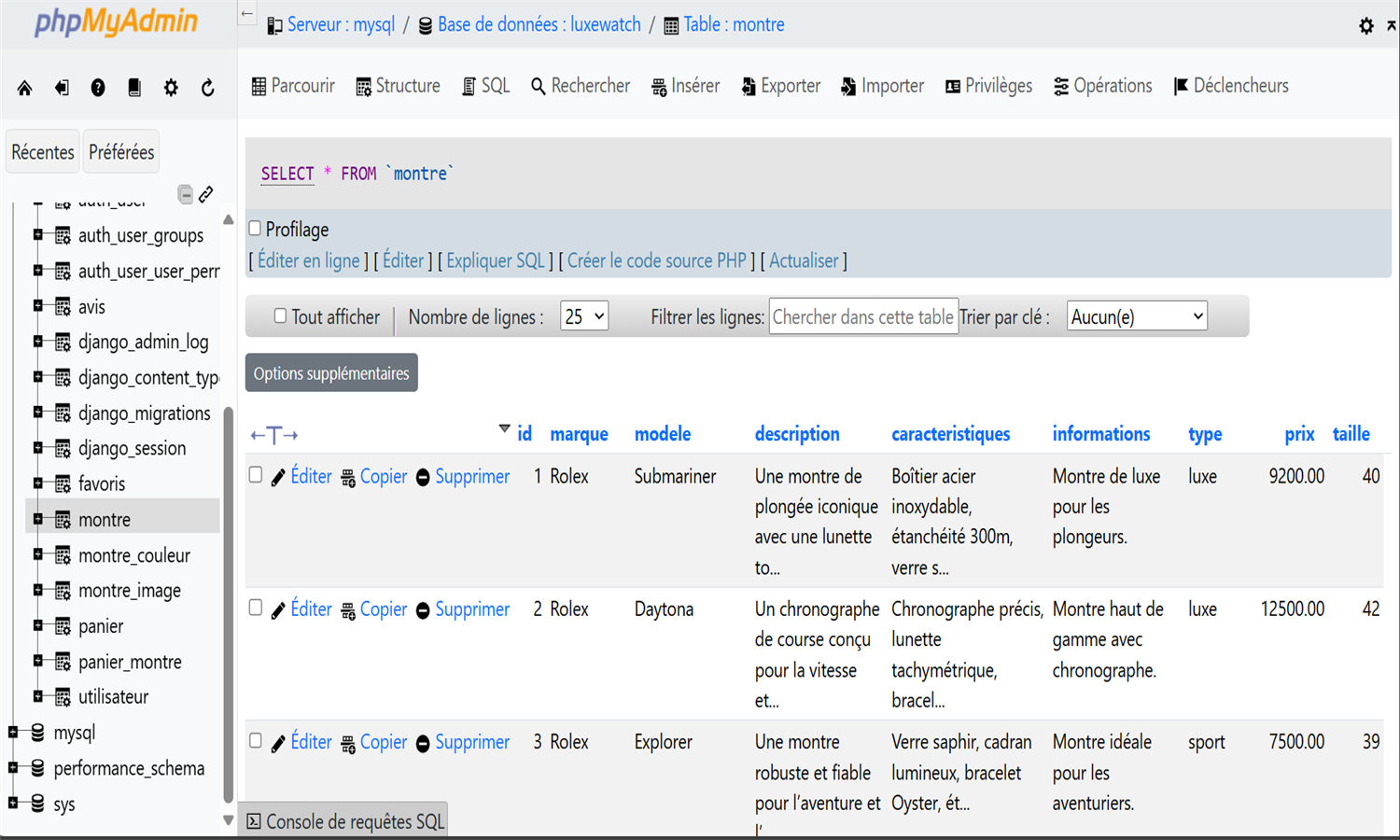
WatchSphere est une plateforme e-commerce développée avec Django, dédiée à la présentation et à la vente de montres de diverses marques. Les utilisateurs peuvent créer un compte, gérer leur profil, consulter les montres par filtres (type, prix, marque), laisser des avis et constituer une liste de favoris. Chaque montre dispose de variantes de couleurs avec image et stock associé. Le panier permet d’ajouter des articles, modifier les quantités et visualiser le total. La base MySQL structure les entités clés comme Utilisateur, Montre, Avis, Favoris et Panier.
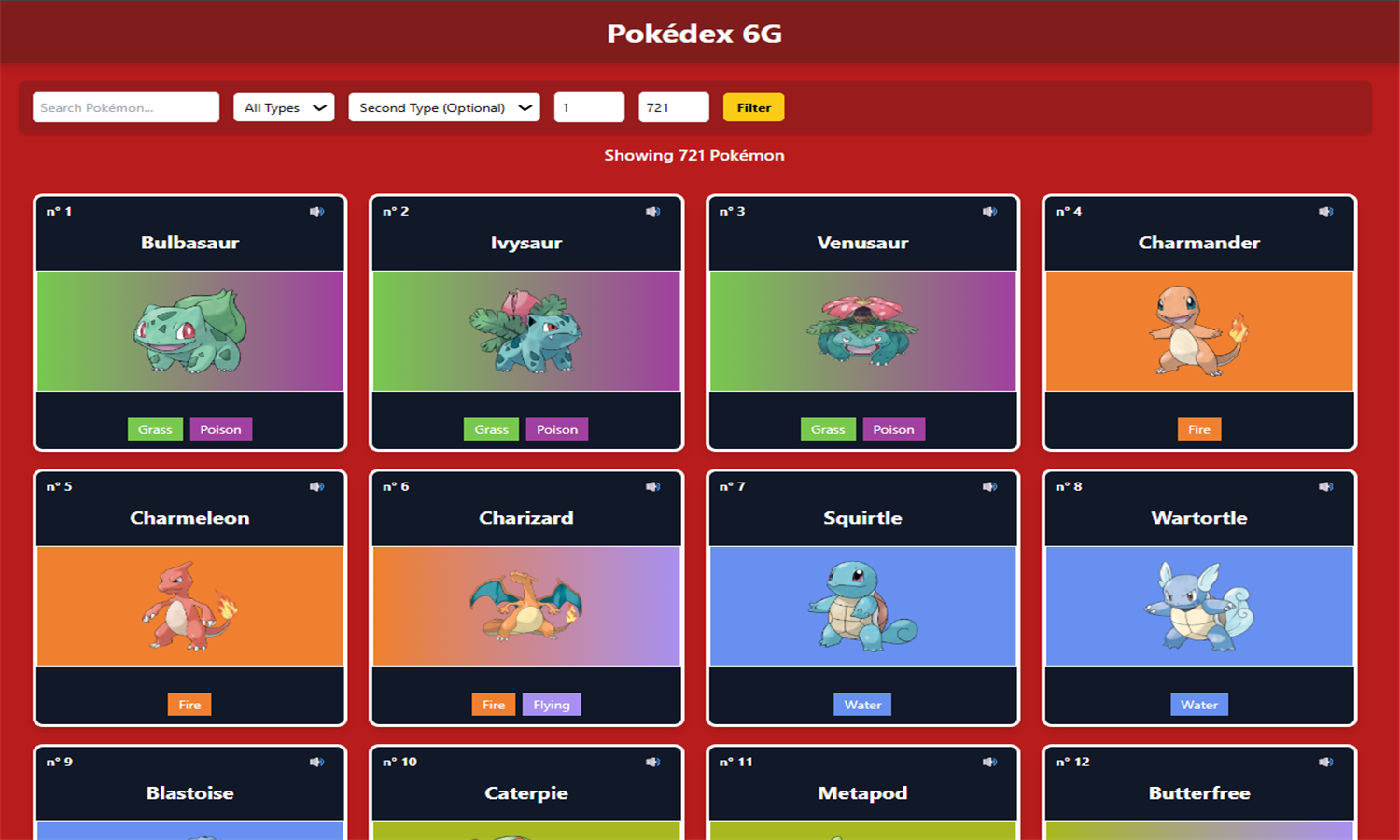
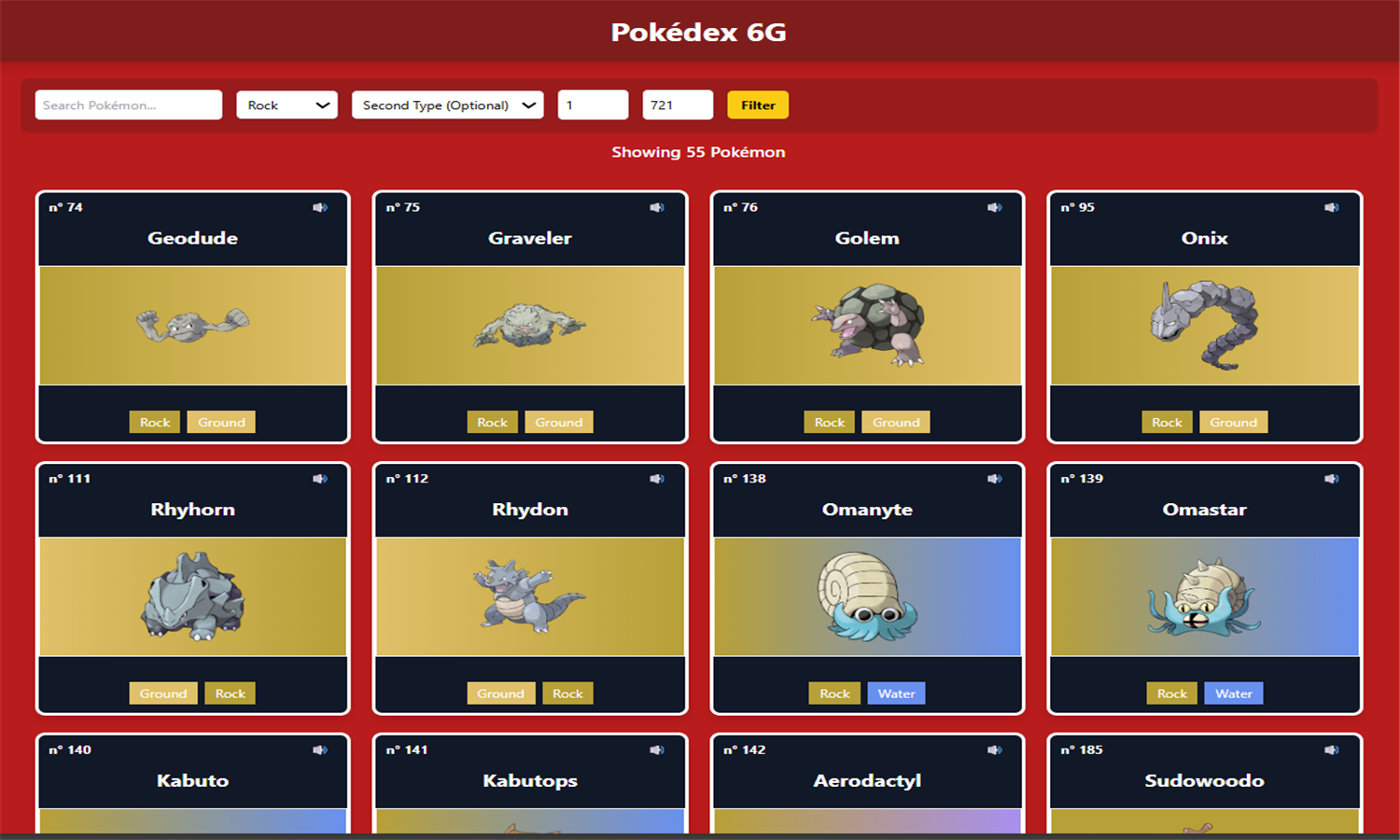
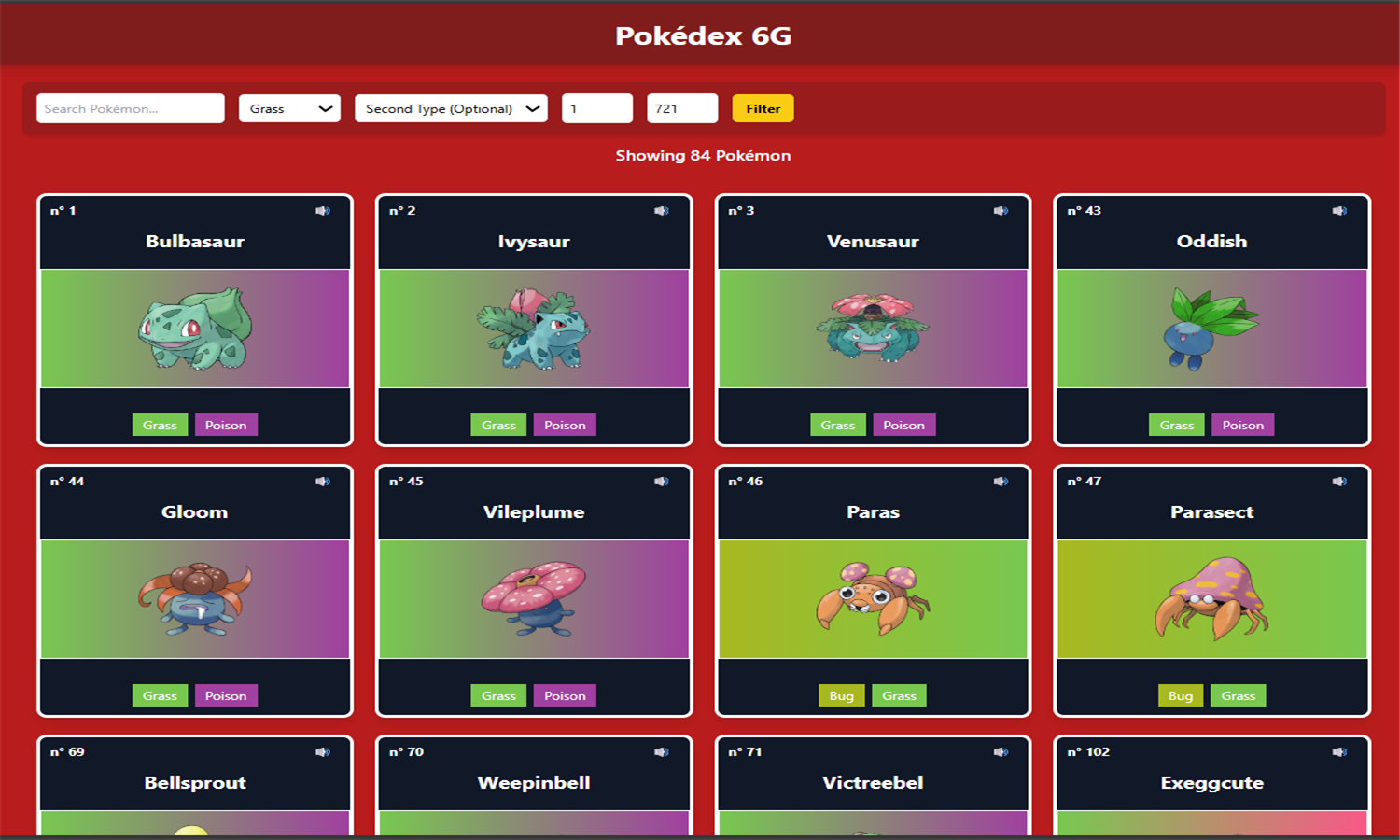
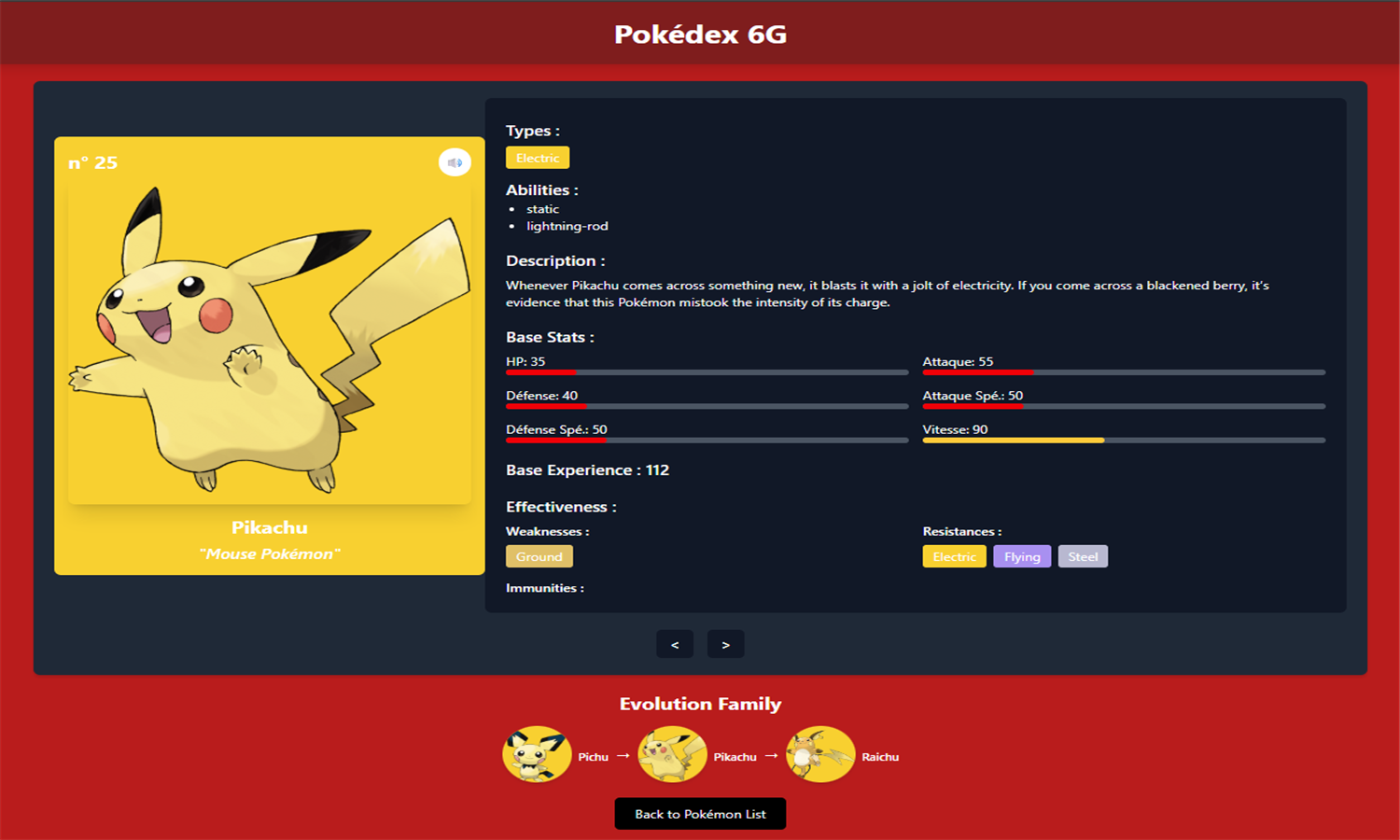
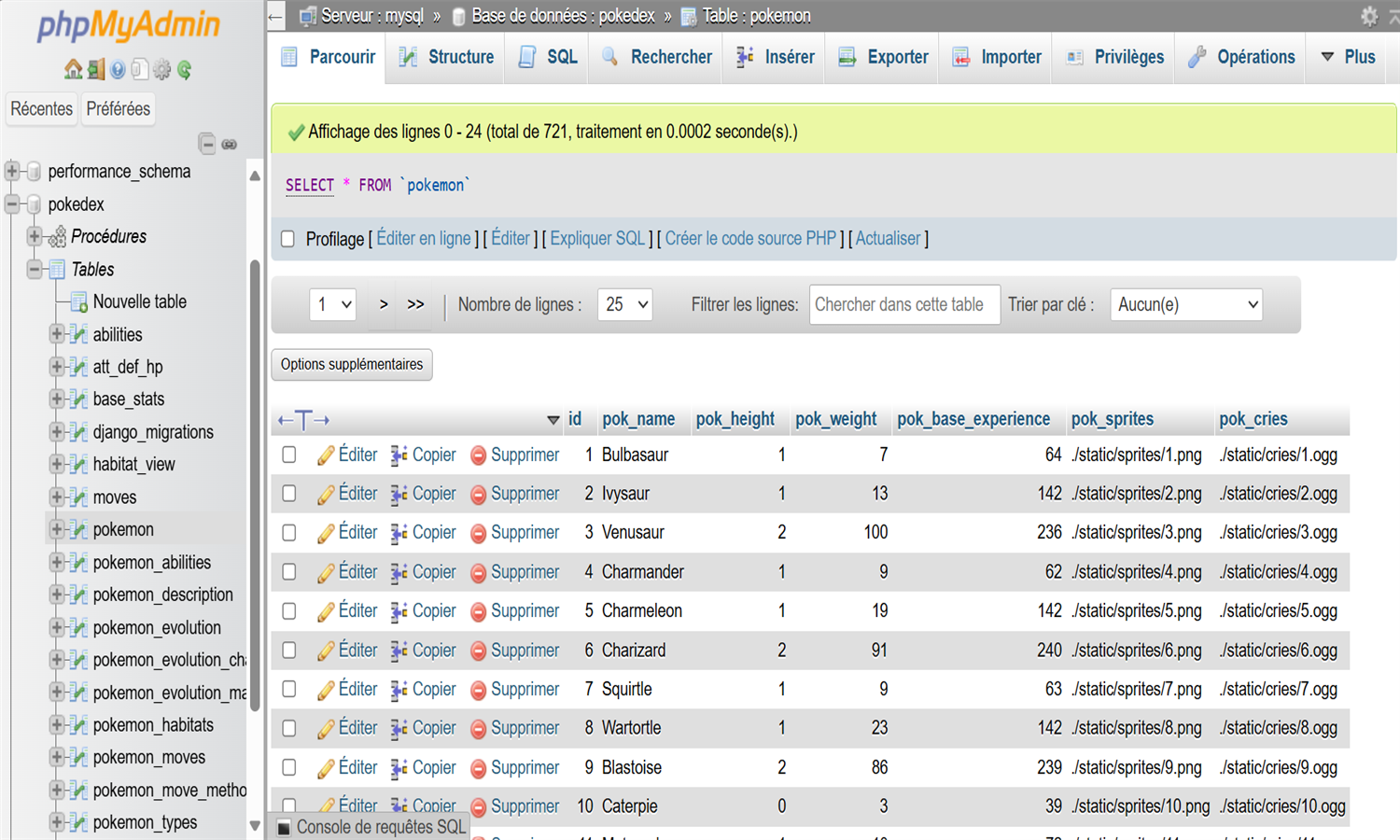
Cette application Django est une base de données enrichie de Pokémon, affichant uniquement ceux des générations 1 à 6. Les données proviennent de la PokéAPI, incluant noms, tailles, poids, statistiques de base, types, capacités, sprites, cris et descriptions. Chaque Pokémon est lié à ses types, capacités (avec statut caché ou non), statistiques, et descriptions textuelles. Les types possèdent également des couleurs personnalisées et une table d’efficacité des types a été ajoutée pour gérer les multiplicateurs de dégâts. Les données ont été restructurées et normalisées pour une gestion relationnelle propre et évolutive.
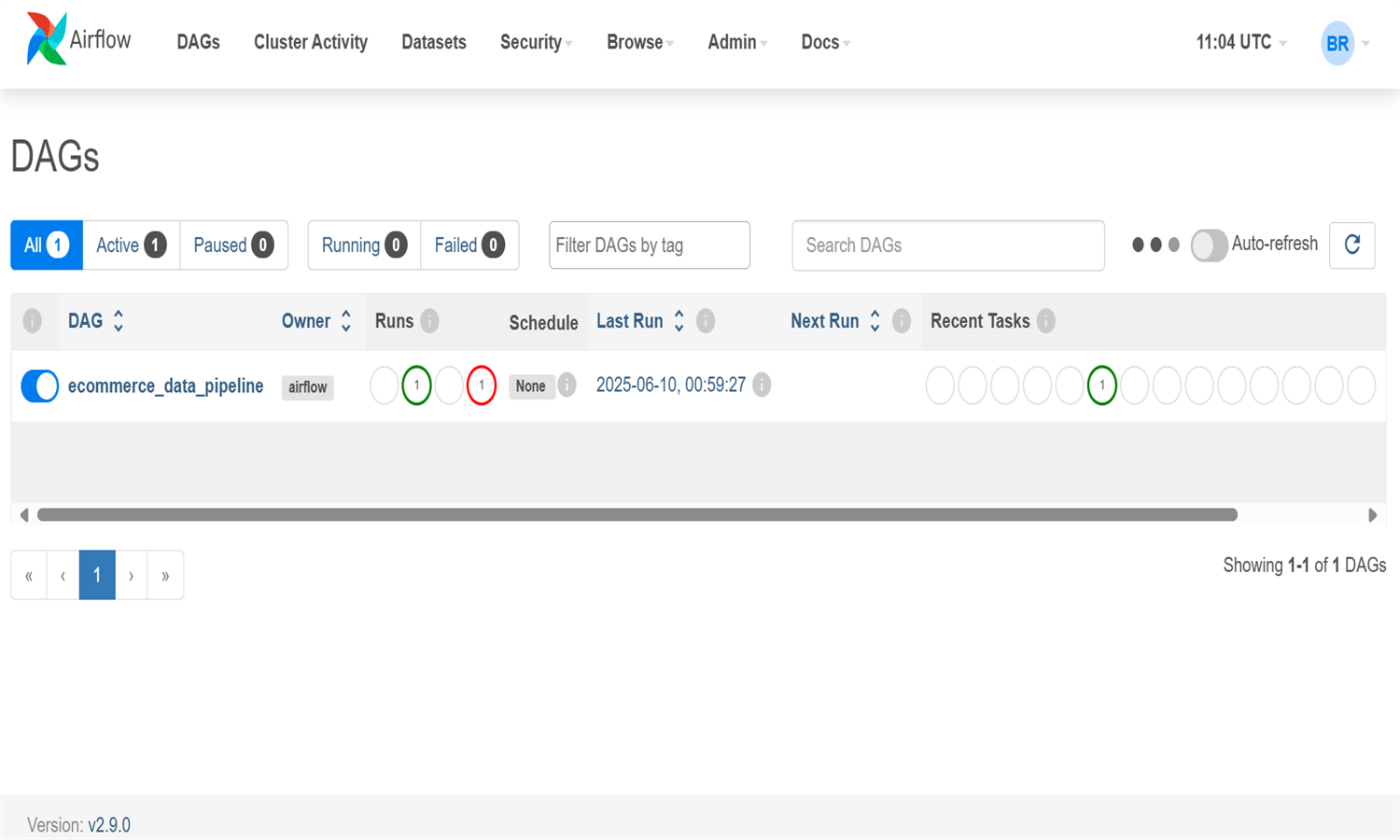
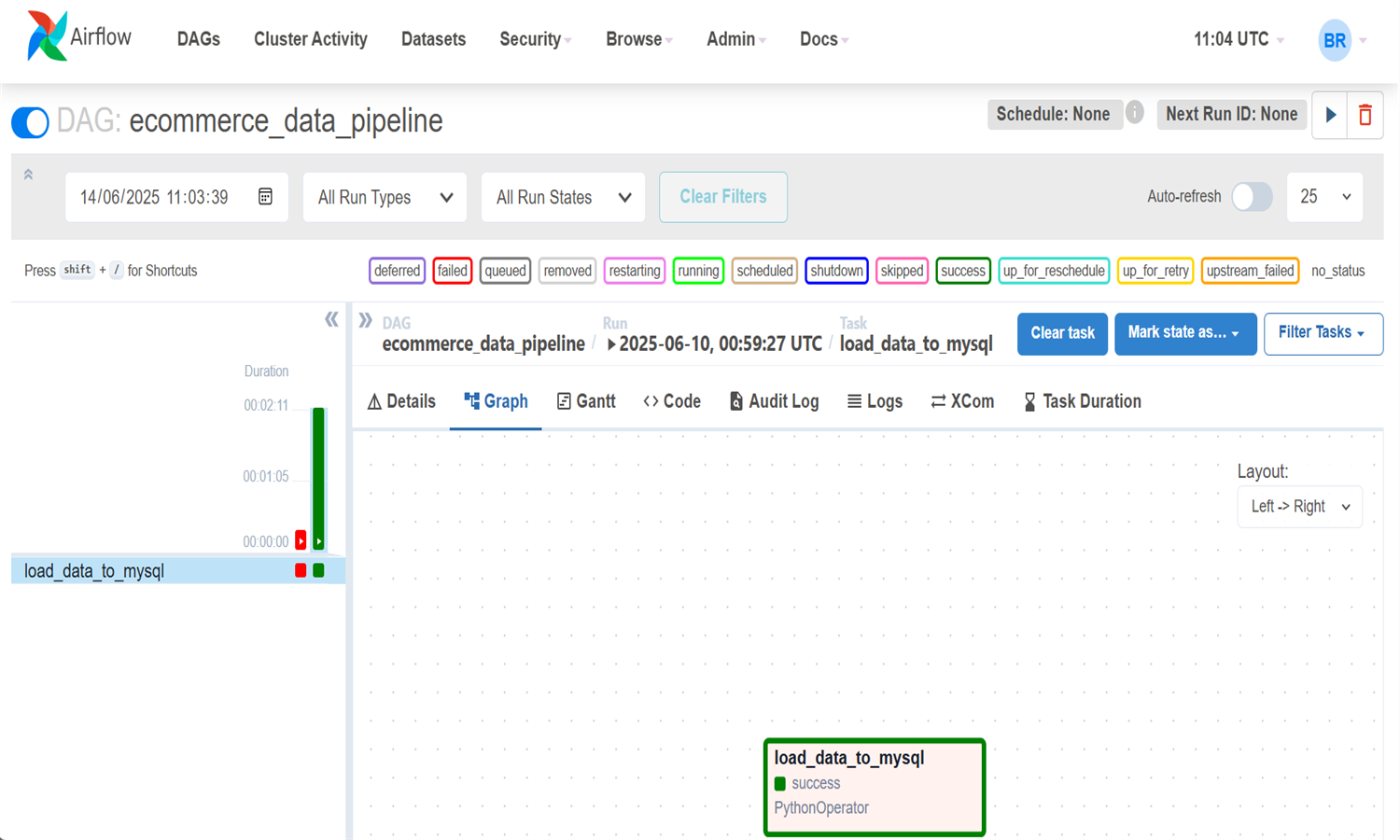
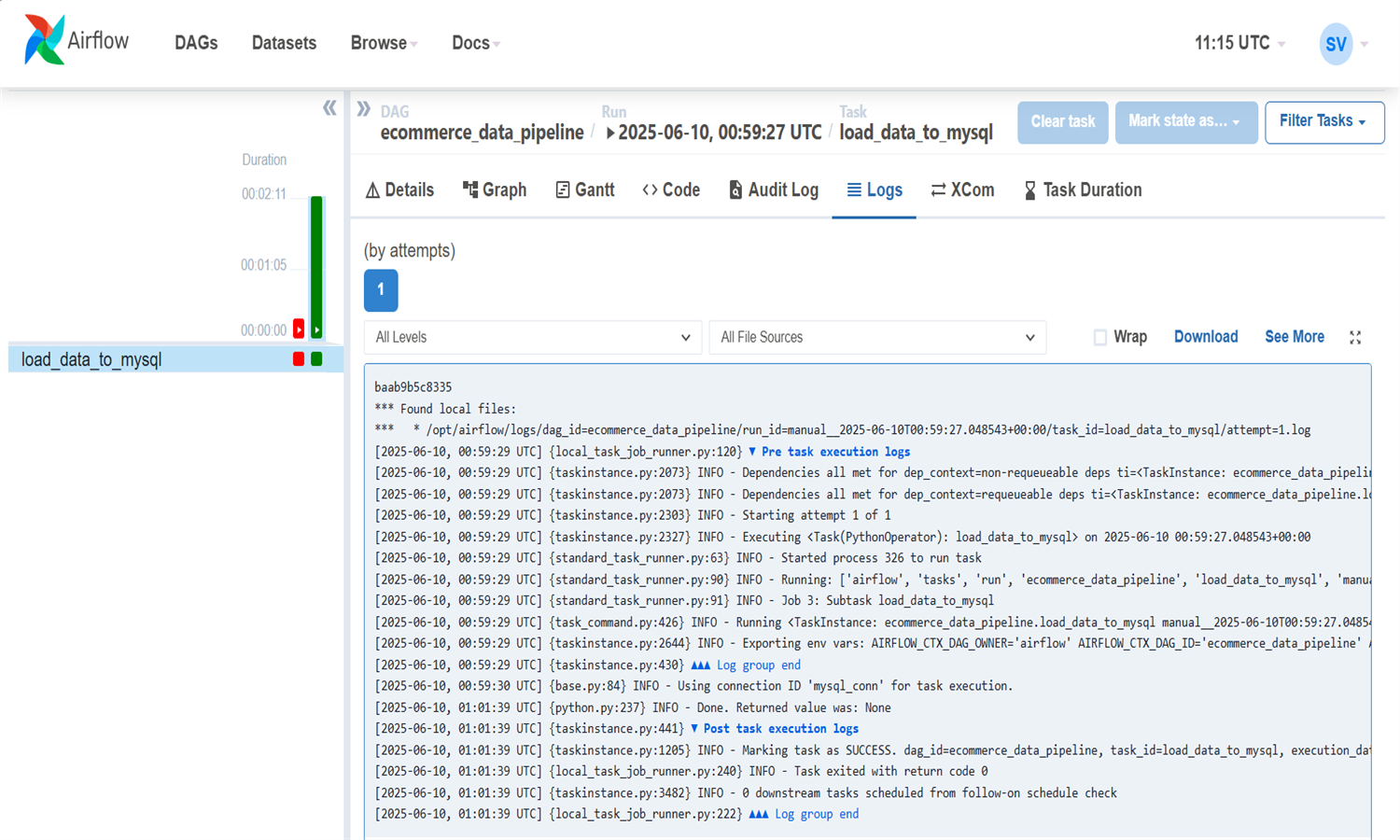
Ce projet met en place un pipeline de traitement automatisé de données e-commerce via Airflow.
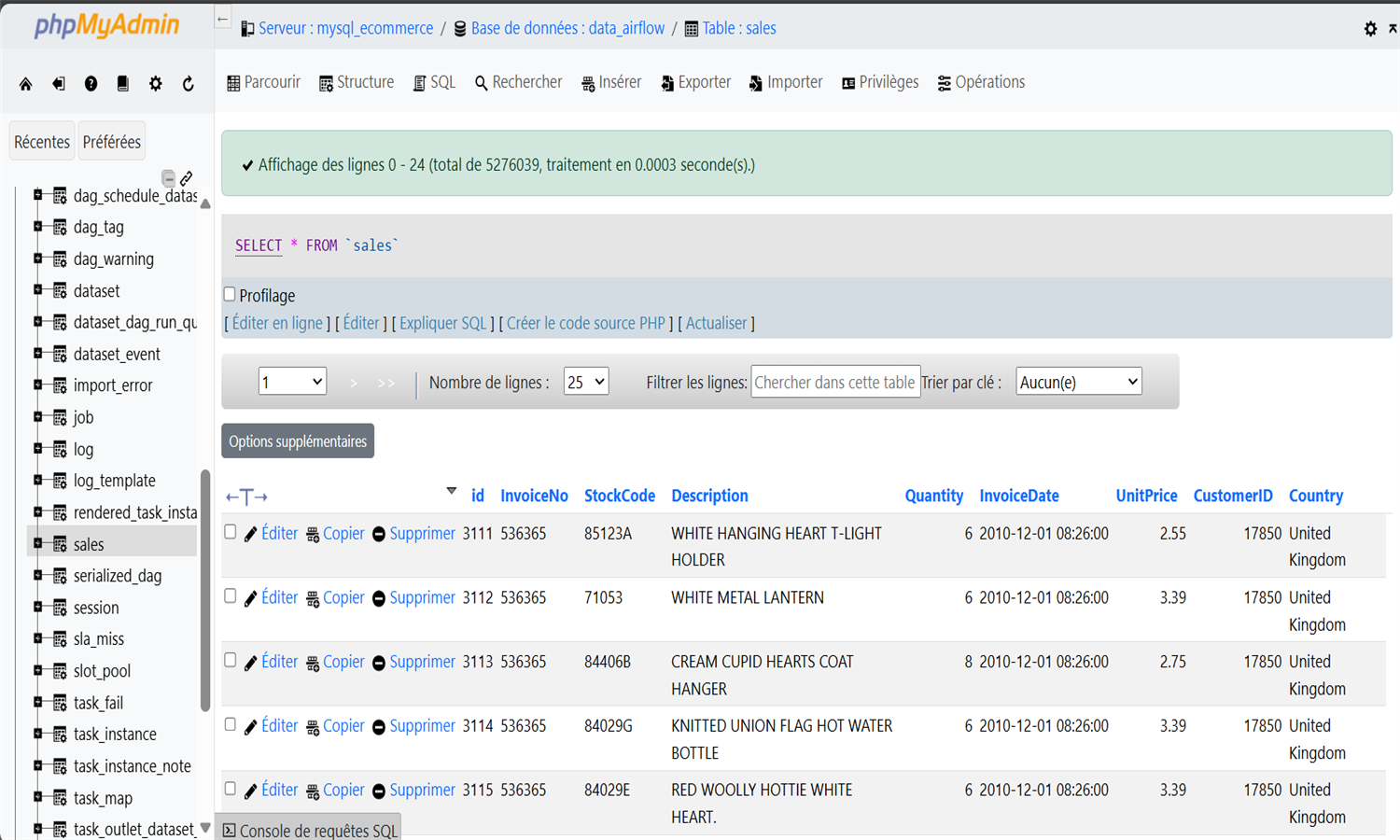
Les données proviennent du fichier "Online Retail II" publié sur UCI Machine Learning Repository par un distributeur en ligne britannique.
Elles couvrent les transactions B2C entre 2010 et 2011, avec des colonnes telles que InvoiceNo, StockCode, Description, Quantity, Price, CustomerID, et Country.
Le fichier Excel est d’abord converti en CSV, puis traité par un script Python intégré dans un DAG Airflow.
Chaque ligne est nettoyée (valeurs manquantes, NaN) via une fonction safe_val avant insertion.
Les données sont stockées dans une base MySQL via une tâche Airflow planifiée quotidiennement à 6h.
Les connexions sont sécurisées et dynamiques via les hooks Airflow pour éviter les informations en dur.
Ce pipeline met en valeur l’automatisation des workflows, le nettoyage de données, et l'intégration continue.
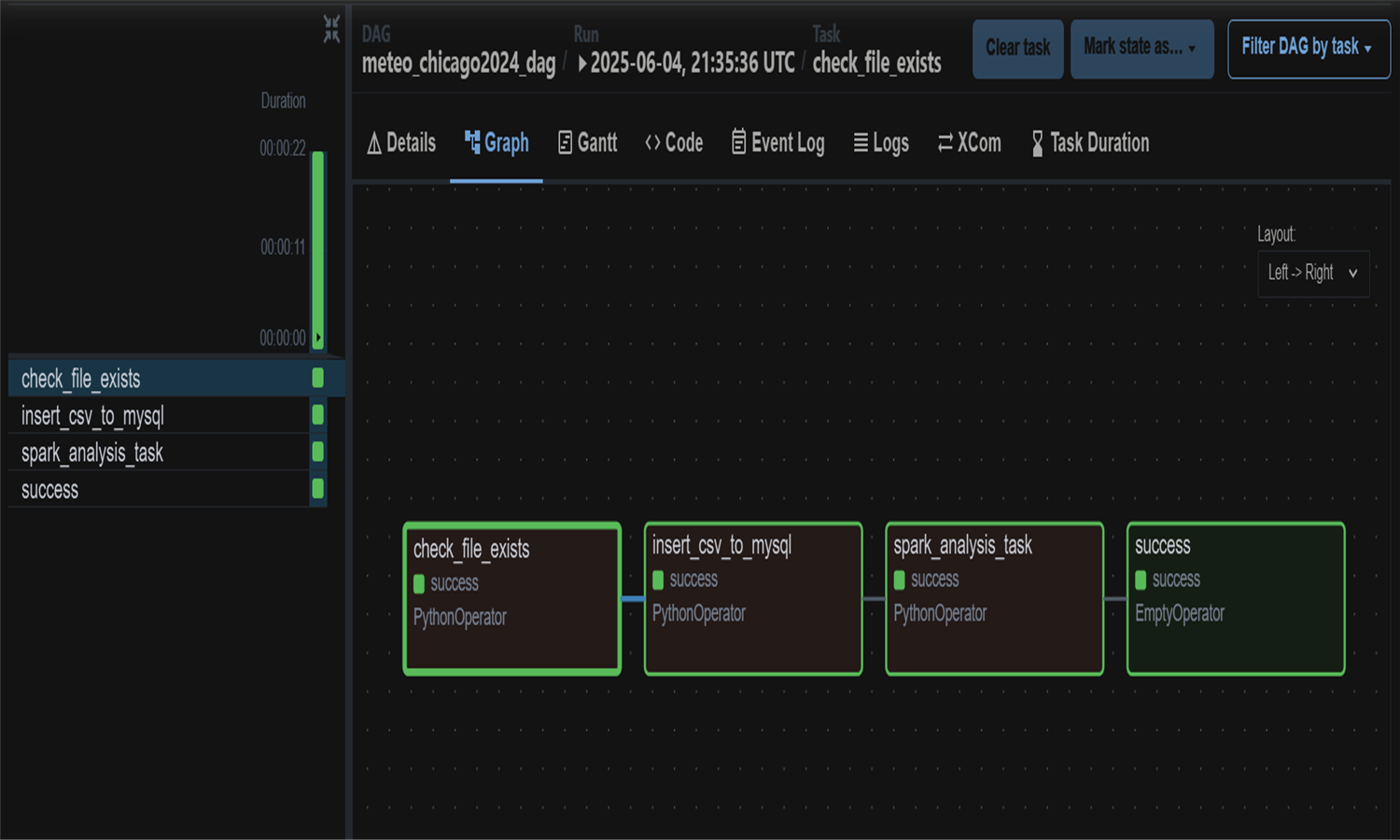
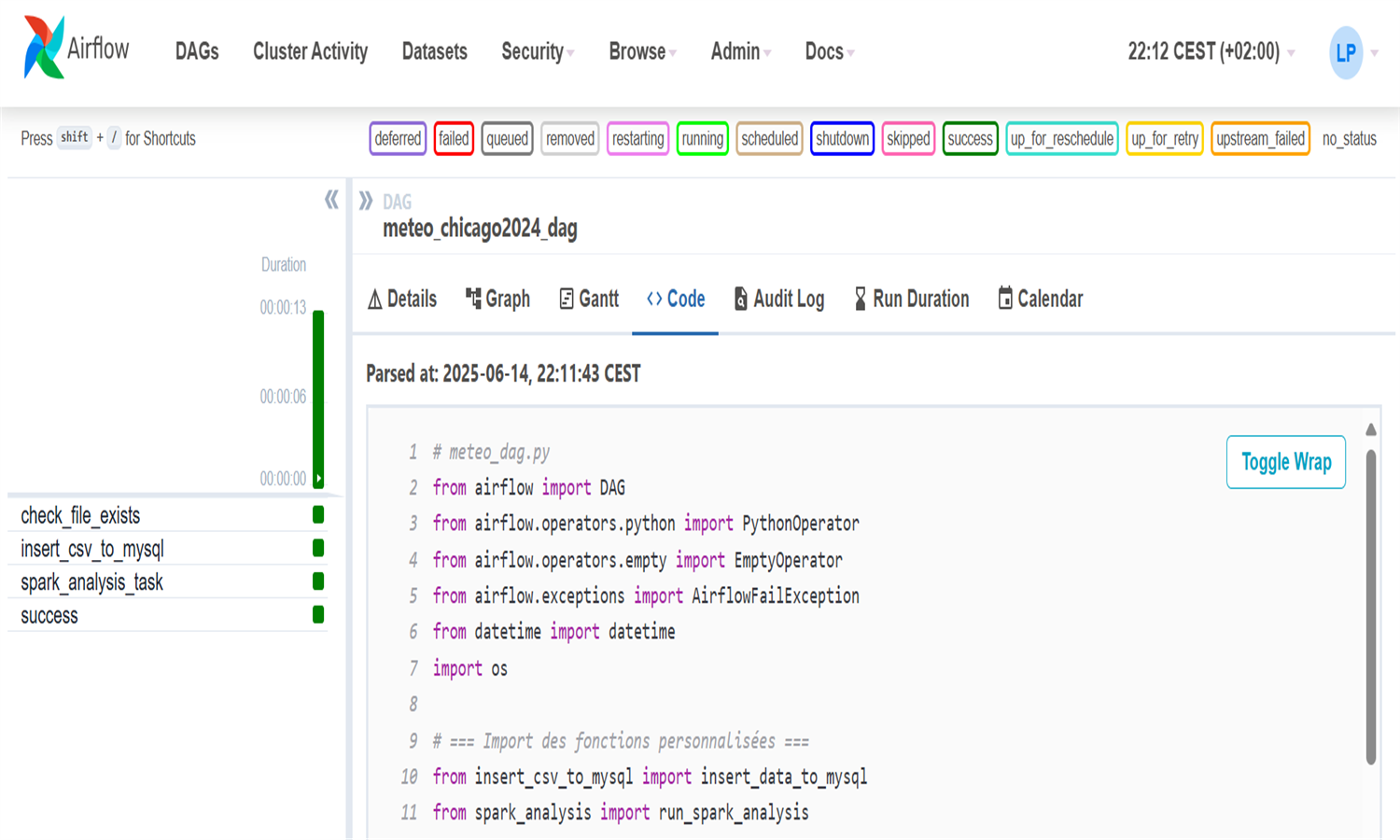
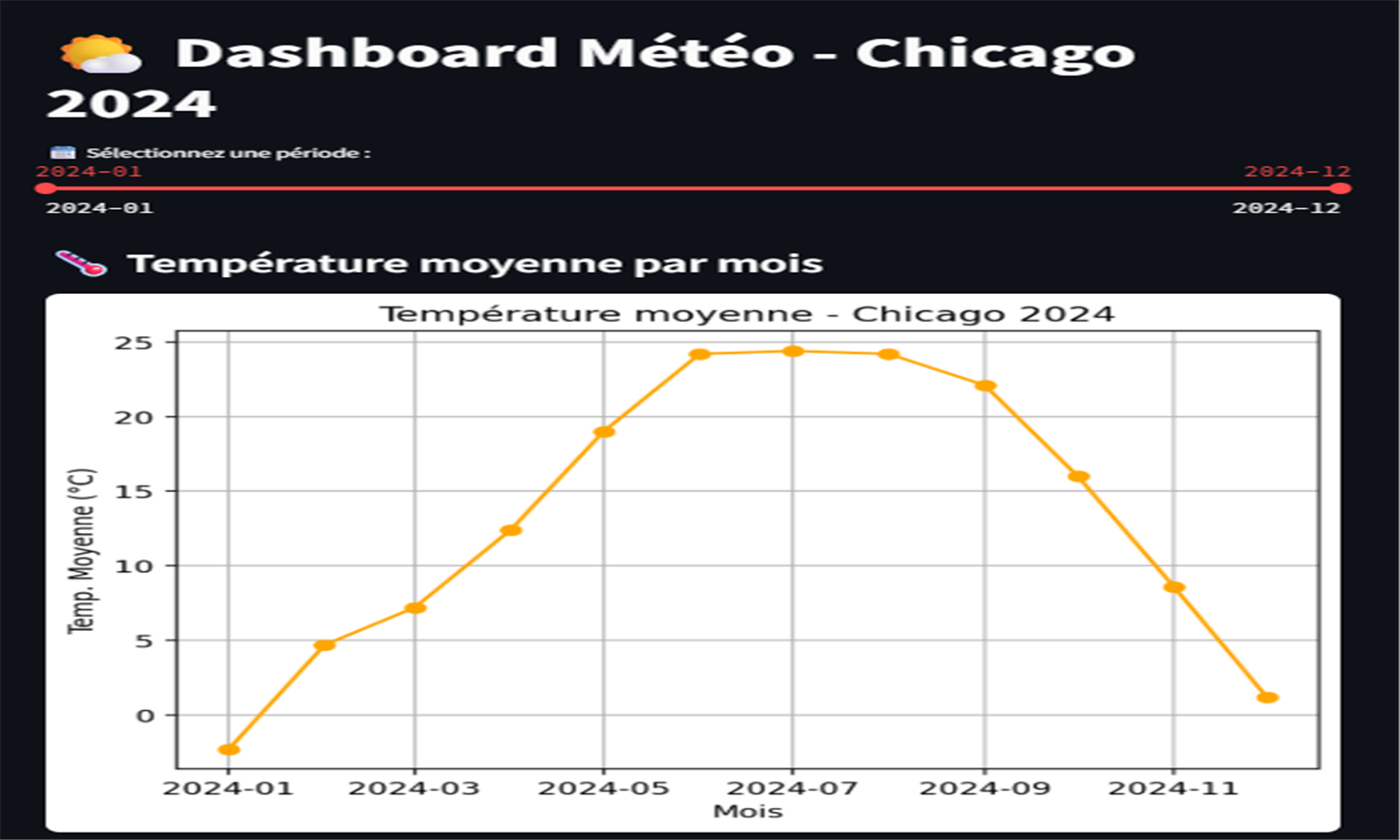
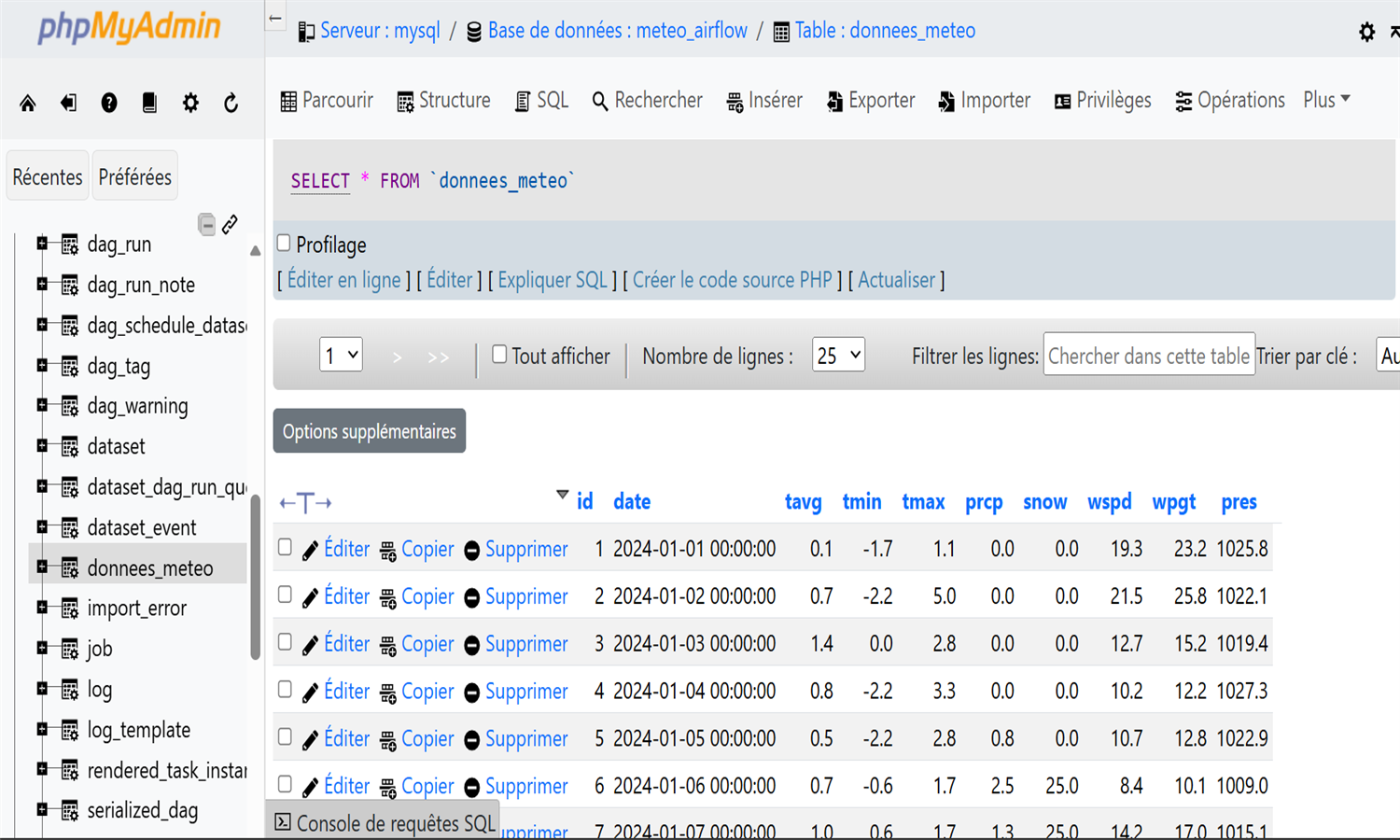
Ce projet construit un pipeline ETL pour analyser les données météo de Chicago en 2024.
Les données brutes en CSV sont vérifiées, insérées dans MySQL, puis analysées via PySpark.
Les statistiques mensuelles (températures, précipitations, jours extrêmes...) sont calculées automatiquement.
Le tout est orchestré par Airflow, conteneurisé avec Docker, et stocké dans une base MySQL.
phpMyAdmin permet de visualiser les données, et un dashboard Streamlit est prévu.
La stack utilise également Redis pour le backend Airflow.
L’objectif est de produire des analyses climatiques fiables dans un environnement reproductible.
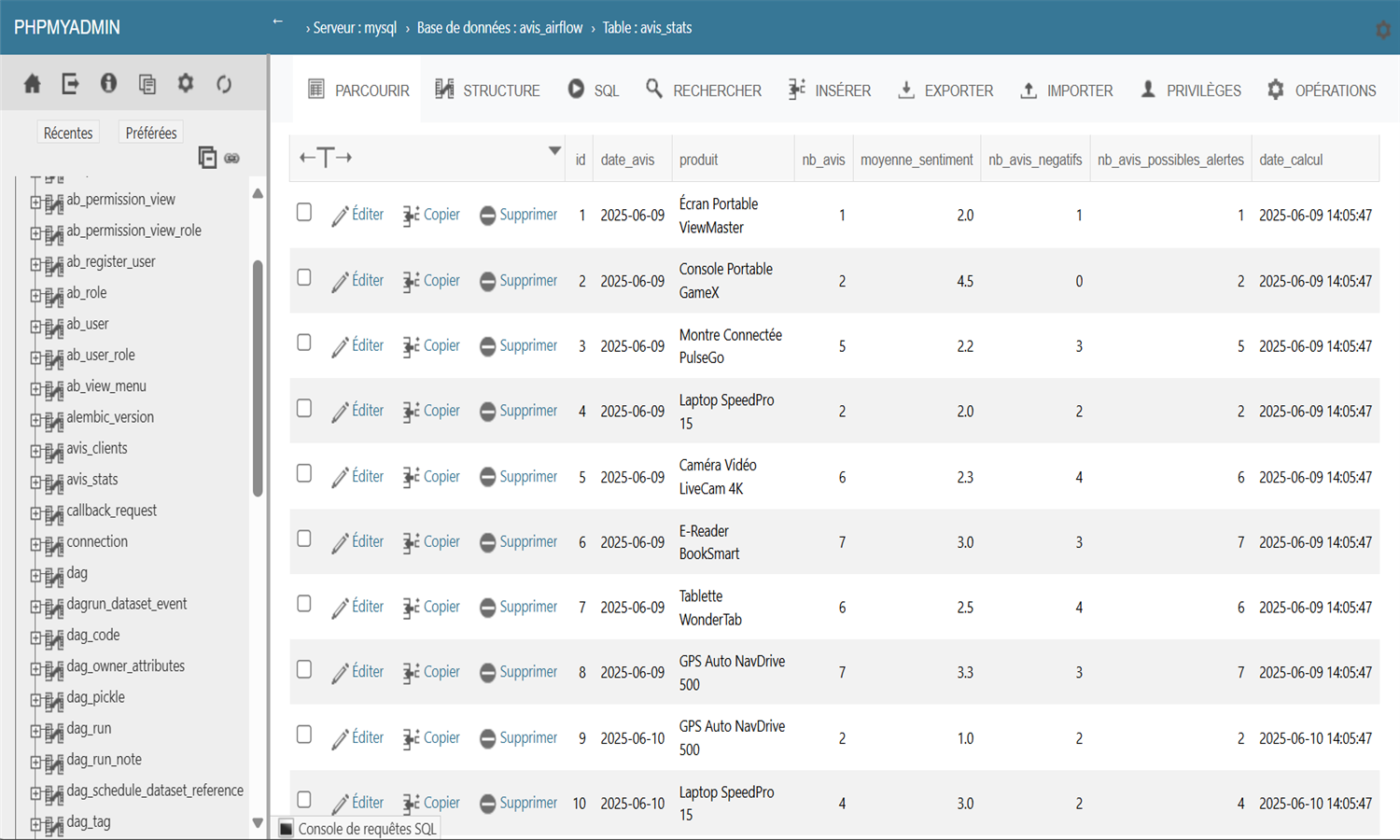
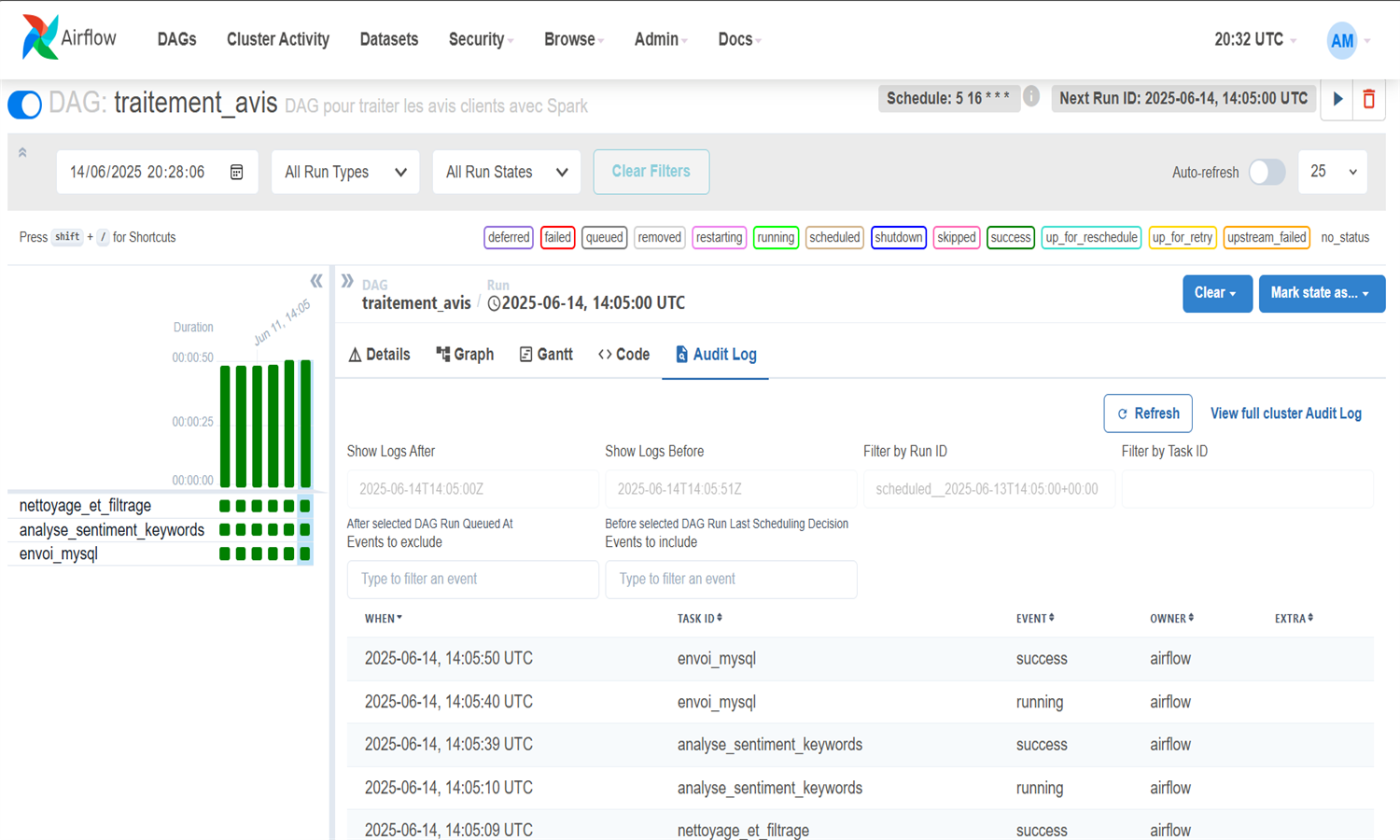
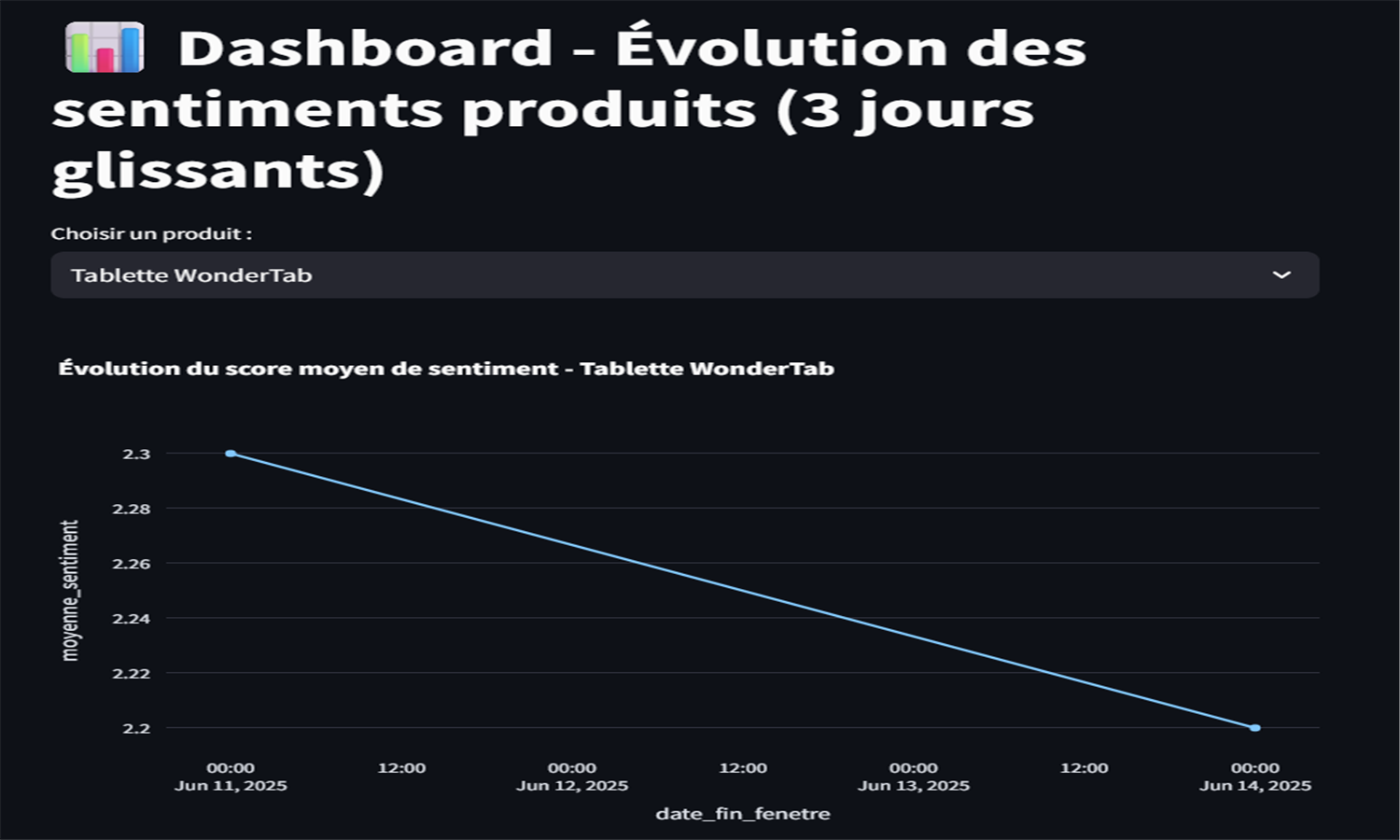
Ce projet met en place un pipeline data engineering complet pour analyser les avis clients et détecter des signaux faibles. Les données sont simulées puis traitées avec Spark (nettoyage, NLP, détection de mots-clés et sentiments), orchestrées via Airflow, et stockées dans MySQL. Une analyse glissante permet de détecter les évolutions de sentiment sur 3 jours. Les résultats sont visualisés dans un dashboard Streamlit interactif. L’infrastructure est entièrement conteneurisée avec Docker Compose. Redis est utilisé pour Airflow, et phpMyAdmin permet d’explorer les données. Chaque étape du pipeline est exécutée quotidiennement à heures fixes.
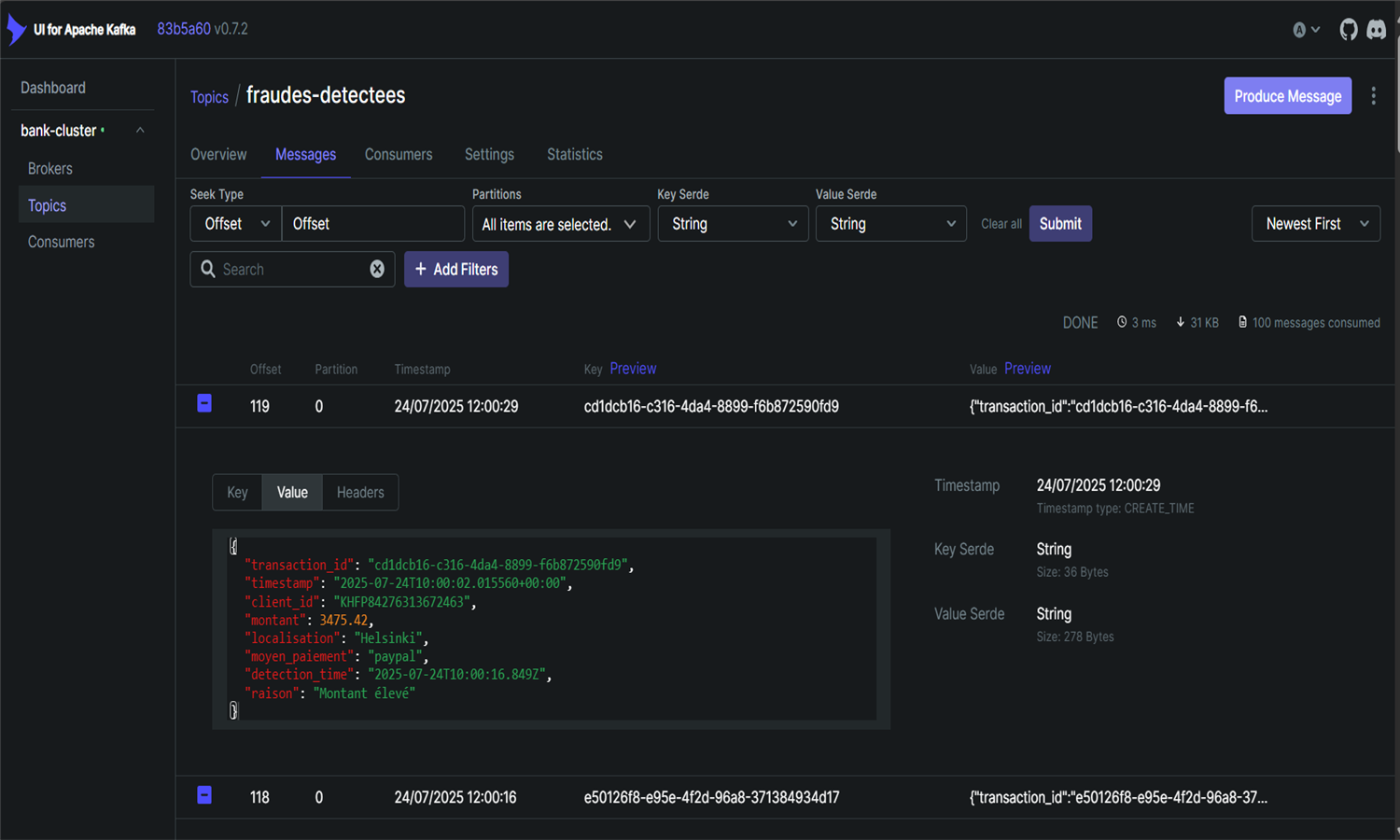
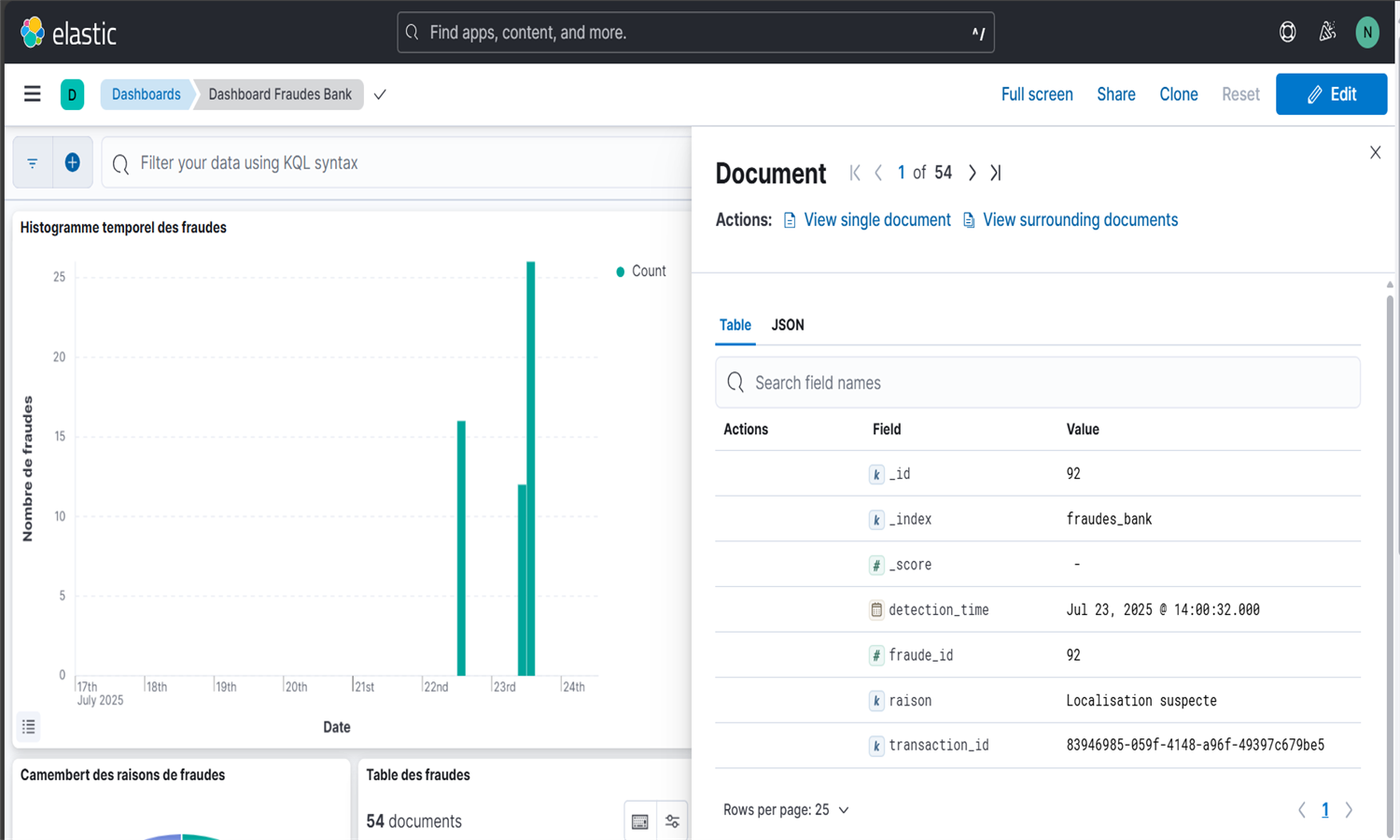
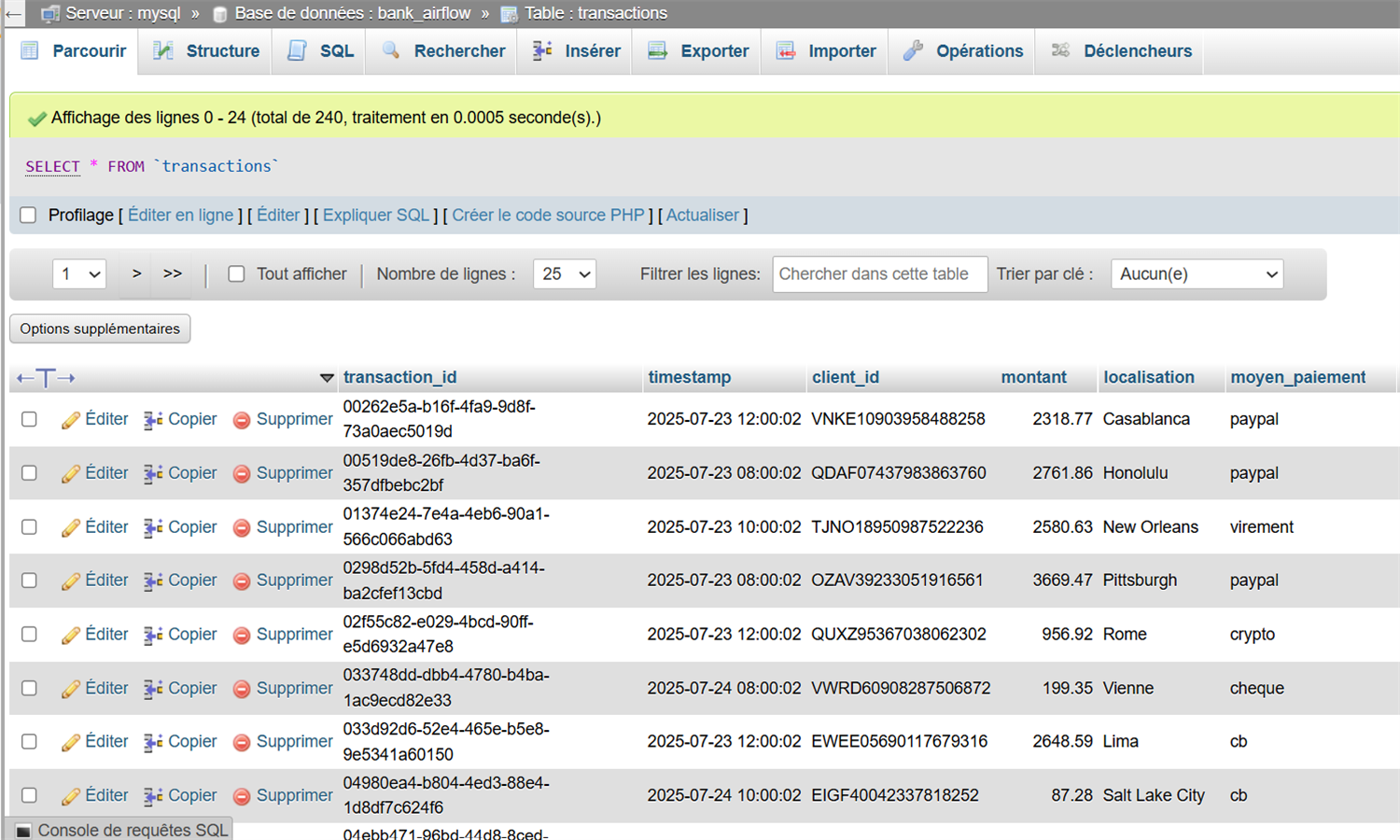
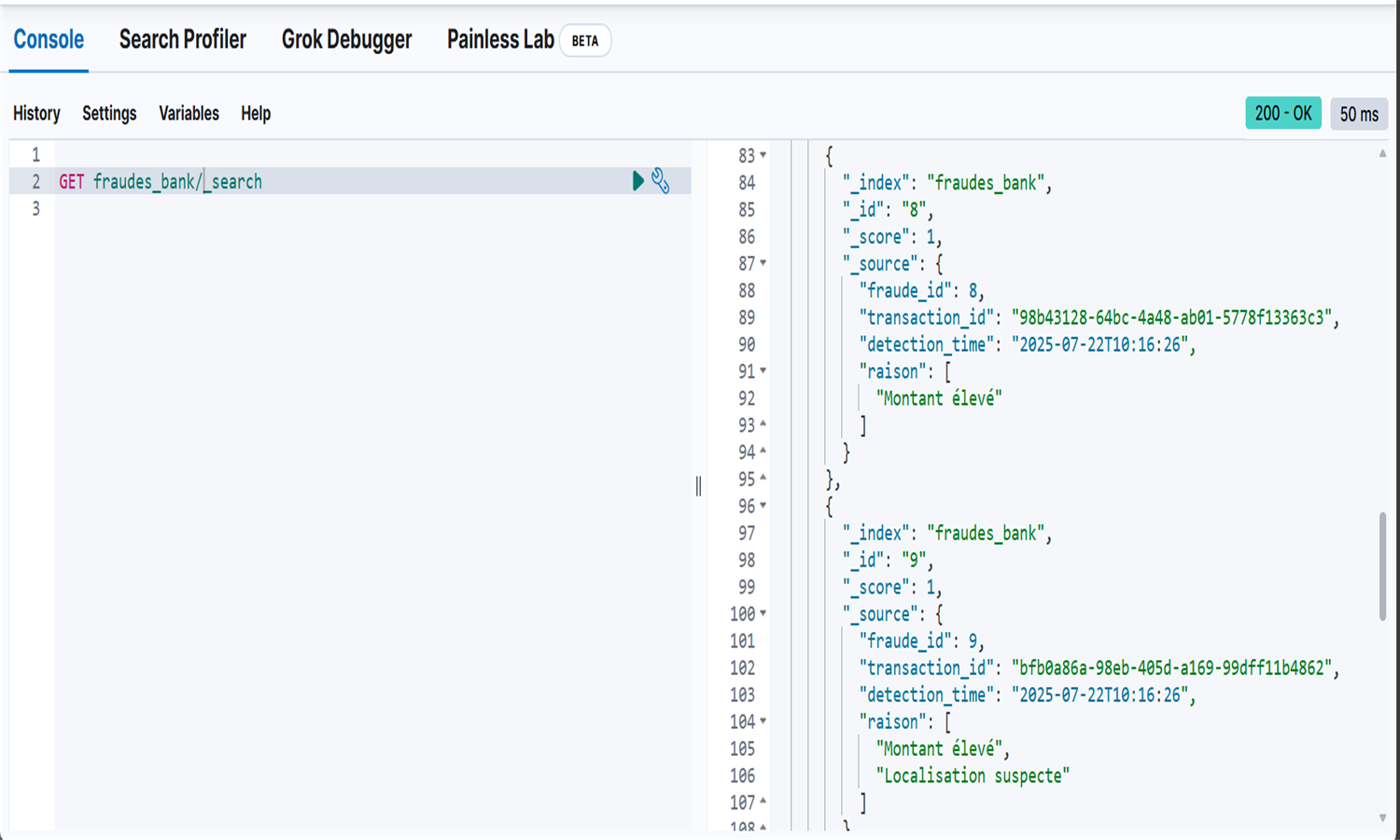
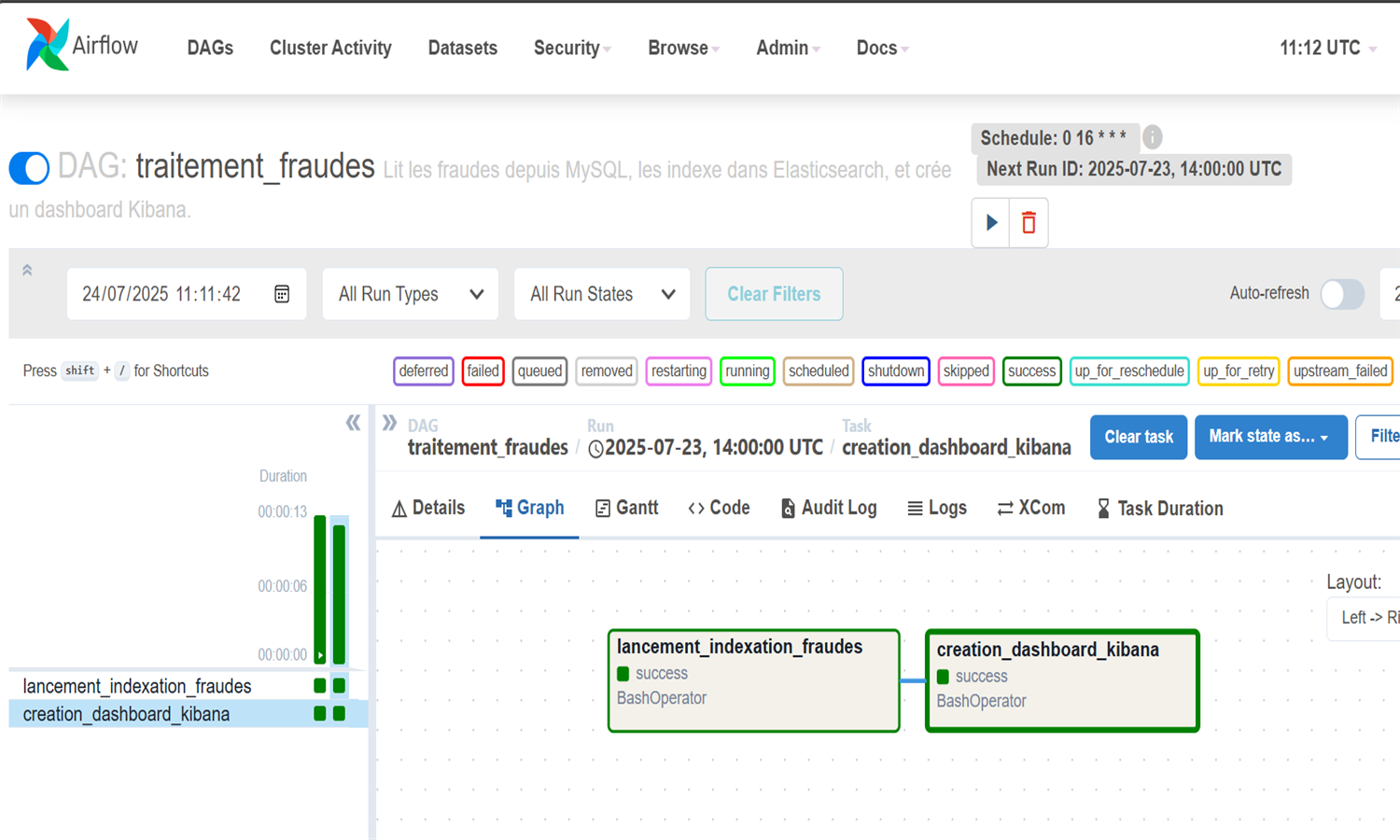
Cette application détecte automatiquement des fraudes bancaires en temps réel via un pipeline complet de streaming. Les données simulées sont envoyées vers Kafka puis traitées par Spark Structured Streaming selon plusieurs critères (montant élevé, localisation douteuse, moyen de paiement). Les fraudes détectées sont stockées dans MySQL et indexées dans Elasticsearch pour être visualisées sur Kibana. L'orchestration des tâches est assurée par Airflow, sauf pour le streaming Spark autonome. Un dashboard Streamlit final permet une analyse interactive des fraudes. L’ensemble est dockerisé pour un déploiement rapide et modulaire.